6 Modèles généralisés additifs
Dans ce chapitre, nous abordons deux formes de modèles généralisés additifs (Generalized additive model – GAM) qui permettent d’introduire l’espace de deux manières différentes : les modèles GAM avec une spline bivariée avec les coordonnées géographiques (x, y) pour capturer les variations continues dans l’espace; les modèles GAM avec un lissage par champ aléatoire de Markov (Markov random field – MRF) pour modéliser la dépendance spatiale entre les unités spatiales voisines.
Objectifs d’apprentissage visés dans ce chapitre
À la fin de ce chapitre, vous devriez être en mesure de :
- comprendre pourquoi utiliser un modèle GAM avec une spline bivariée sur les coordonnées géographiques ou avec un lissage par champ aléatoire de Markov;
- analyser les résultats produits par ces deux types de modèles GAM;
- mettre en pratique ces modèles dans R.
Liste des packages utilisés dans ce chapitre
- Pour importer et manipuler des fichiers géographiques :
sfpour importer et manipuler des données vectorielles.
- Pour mesurer l’autocorrélation :
spdeppour construire des matrices de pondération spatiales et calculer le I de Moran.
- Pour construire des cartes et des graphiques :
ggplot2pour construire des graphiques.tmapest certainement le meilleur package pour la cartographie.
- Pour construire des modèles GAM :
mgcv, le package de référence pour ajuster des modèles GAM. De nombreux autres packages proposent des extensions pour ce type de modèle et se basent principalement sur les outils mis à disposition parmgcvpour créer des bases et leurs matrices de pénalisation (gamm4,brms,gamlss,qgam, etc.).DHARMa, un package permettant d’effectuer des diagnostics sur des résidus de modèles GLM.
6.1 Bref retour sur les GAM
Les modèles généralisés additifs (GAM) constituent une famille de modèles de régression très flexibles permettant notamment de modéliser des relations non paramétriques entre les variables indépendantes et la variable dépendante.
Dans un modèle de régression classique, nous partons du principe que les variables \(\mathbf{X}\) (indépendantes) ont un impact linéaire sur la variable \(\mathbf{Y}\) (dépendante). Cette hypothèse simplifie grandement les relations entre les variables observées et permet d’interpréter les résultats plus facilement (analyse des coefficients de régression). Or, cette hypothèse peut être fausse et les relations non linéaires ont plus tendance à être la norme que l’exception.
Dans un GAM, plutôt que modéliser une relation linéaire, nous partons du principe que la relation modélisée peut être non linéaire et suivre une fonction \(f\). Il s’agit alors de relations non paramétriques, car la forme de cette fonction s’ajuste aux données et ne suit pas une forme prédéterminée.
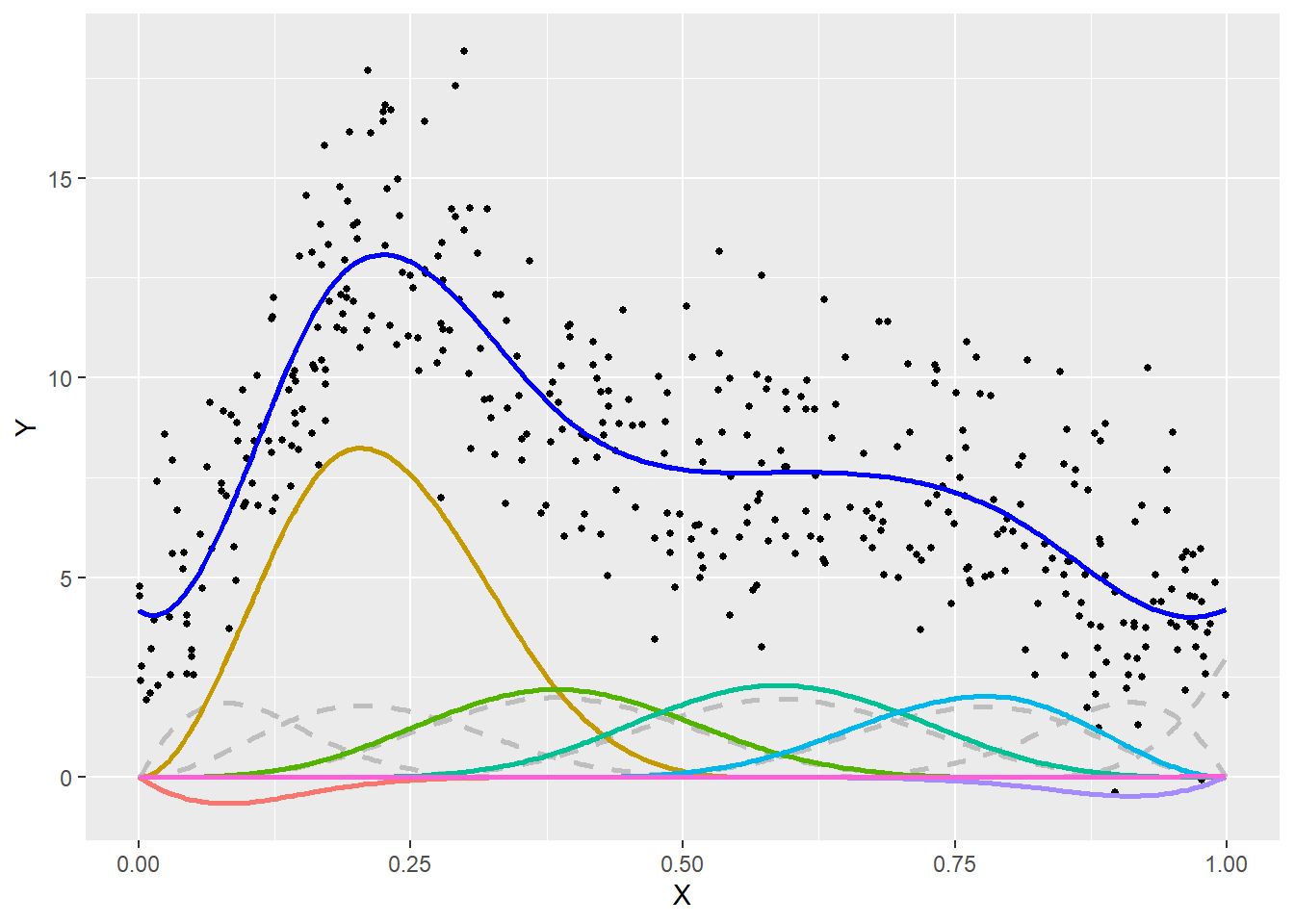
Ces fonctions \(f\) sont le plus souvent estimées avec des splines. Le fonctionnement de base est assez simple. Pour chaque variable \(\mathbf{X}\) devant suivre une relation non linéaire, la variable est remplacée par \(k\) sous-variable (\(x_1\), \(x_2\), …, \(x_k\)). \(k\) représente le niveau de complexité attendu de la relation : plus il est grand, plus l’ajustement de la fonction est complexe. Le modèle estime un coefficient pour chacune de ces sous-variables, et la somme des effets de ces sous-variables permet de reconstruire la relation non linéaire.
La figure 6.1 permet d’illustrer ce principe. Les lignes grises représentent les sous-variables, aussi appelées bases, qui sont ensuite multipliées par leur coefficient respectif pour obtenir leurs effets (en couleur), puis la ligne bleue représente leur somme. La ligne bleue capture très efficacement la relation entre les variables \(\mathbf{X}\) et \(\mathbf{Y}\).
Modèles généralisés additifs
Pour une explication détaillée du fonctionnement des splines, vous pouvez consulter le chapitre sur les GAM du livre Méthodes quantitatives en sciences sociales : un grand bol d’R (Apparicio et Gelb 2022).
6.2 Comment utiliser une spline pour ajouter l’espace dans un modèle GAM?
Nous avons vu qu’une spline permet de modéliser l’impact potentiellement non linéaire d’une variable indépendante sur une variable dépendante. Or, il est possible d’utiliser des splines pour intégrer un effet spatial dans un modèle, et ce, en utilisant un type de spline particulier : la spline bivariée qui capture l’effet simultané de deux variables indépendantes sur une variable dépendante.
Dans un contexte spatial, une spline bivariée capture la façon dont un changement dans les coordonnées X et Y affecte la variable dépendante. De plus, compte tenu de la forme des fonctions de base utilisées, les splines sont particulièrement adaptées pour capturer des relations spatiales avec une forte autocorrélation spatiale positive.
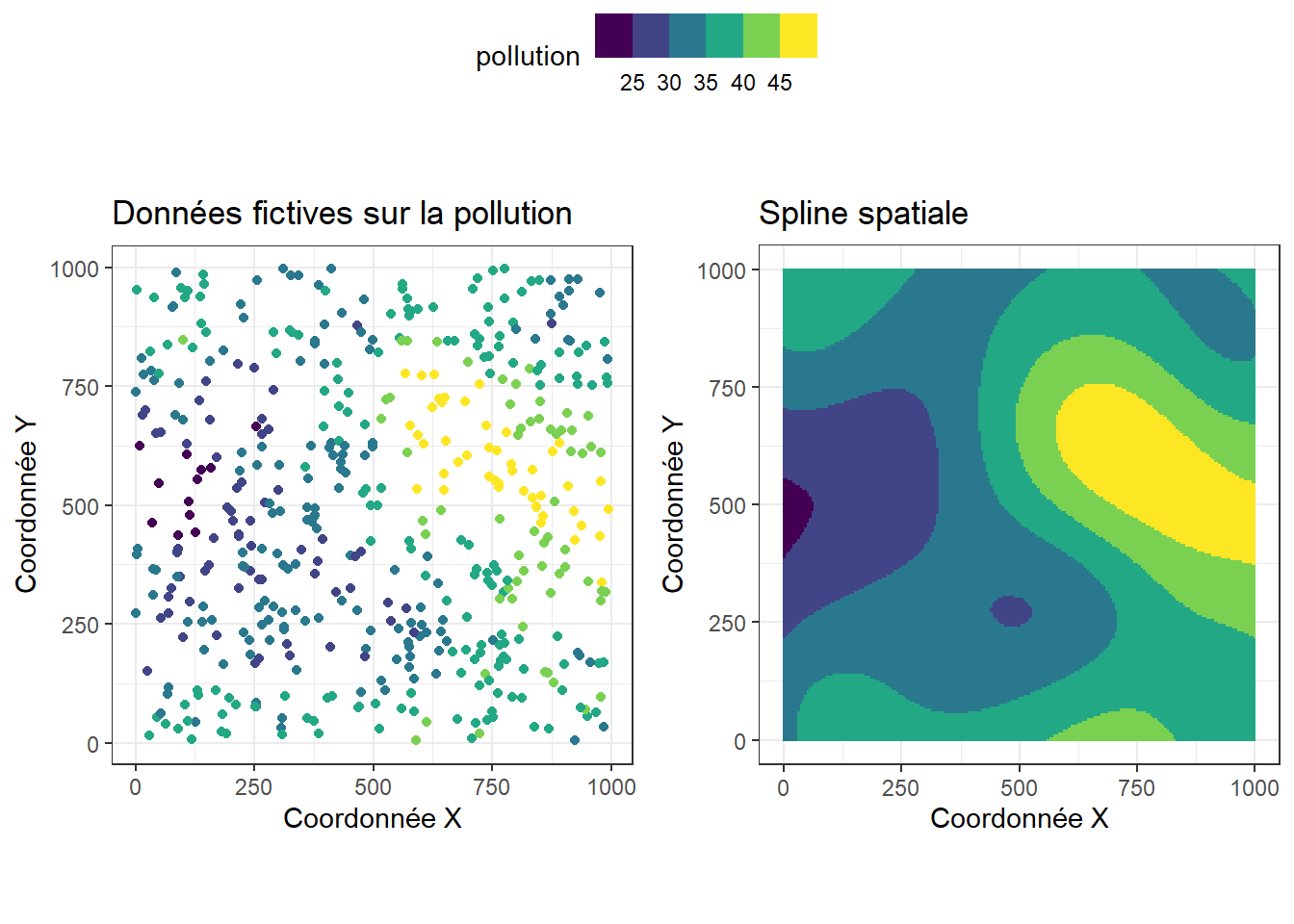
Prenons un exemple avec un jeu de données fictif représentant des mesures de pollution relevées à différentes localisations sur un territoire (figure 6.2).
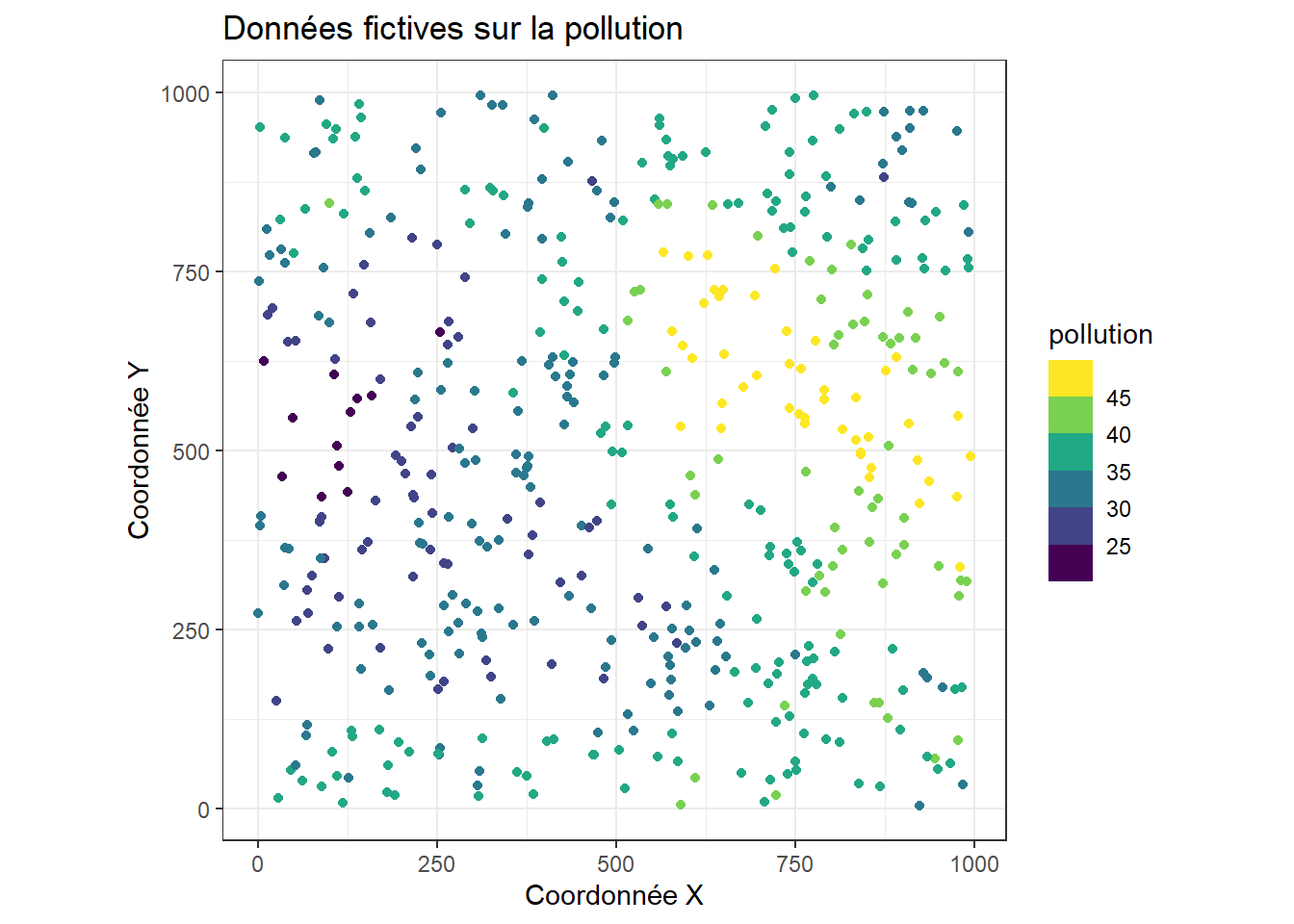
Nous pourrions créer des bases d’une spline qui varient à la fois dans les coordonnées spatiales X et Y. L’animation à la figure 6.3 illustre des bases obtenues (k = 25) pour les données ci-dessus. La hauteur dans la figure est utilisée pour représenter la variation originale des bases qui sera ensuite ajustée aux données grâce aux coefficients du modèle de régression.
En ajustant un coefficient pour chaque base et en combinant leurs effets, nous obtenons un effet spatial permettant de prédire la variable de pollution, cartographié à la figure 6.4. Nous constatons ainsi que le modèle a été capable de reproduire les tendances principales des niveaux de pollution en retrouvant les secteurs avec des valeurs fortes et faibles. Plus l’autocorrélation spatiale est élevée, plus ce type de modèle est efficace pour capturer l’effet spatial.
D’un point de vue plus formel, un modèle GAM peut être décrit par l’équation suivante :
\[ \begin{aligned} &y \sim D(\mu,\theta)\\ &g(\mu) = \beta_0 + \beta X + \sum^{n}_{j=1}(f_j(\zeta_j))\\ \end{aligned} \tag{6.1}\]
avec :
- \(y\), la variable dépendante.
- \(D\), une distribution avec une espérance \(\mu\) et ses autres paramètres \(\theta\).
- \(X\), les variables indépendantes dont l’effet est supposé linéaire par le modèle.
- \(\beta\), les coefficients des variables indépendantes.
- \(\beta_0\), la constante.
- \(\zeta\), les variables dont l’effet est supposé non linéaire par le modèle.
- \(f_j\), une fonction modélisant l’impact de la variable \(\zeta_j\).
Pour un modèle incluant seulement une spline bivariée sur les coordonnées géographiques des observations, le modèle peut se résumer à l’équation suivante :
\[ \begin{aligned} &y \sim D(\mu,\theta)\\ &g(\mu) = \beta_0 + \beta X + f(sp)\\ \end{aligned} \tag{6.2}\]
avec \(sp\) une matrice comprenant deux colonnes, soit les coordonnées cartésiennes des observations.
6.3 Pourquoi recourir à un modèle GAM?
Les modèles GAM sont très flexibles puisqu’ils sont une extension directe des modèles linéaires généralisés (GLM). Ils peuvent donc être appliqués à des variables dépendantes suivant de nombreuses distributions (normale, gamma, binomiale, Poisson, Tweedie, log-normal, etc.). Cependant, ils imposent une conceptualisation particulière de l’espace. En effet, un modèle GAM n’inclut pas directement la notion de dépendance spatiale dans sa formulation. L’hypothèse d’indépendance des observations est conservée (contrairement à un modèle des moindres carrés généralisés, GLS). Le modèle intègre simplement un terme flexible correspondant à l’ajout d’un ensemble de nouvelles variables \(\mathbf{X}\) structurées afin de capturer un effet avec une autocorrélation spatiale positive.
Si nous reprenons l’exemple de la pollution atmosphérique, le modèle est un simple GLM dans lequel nous supposons que les niveaux de pollution suivent une distribution normale et que les observations sont indépendantes. Cependant, la moyenne de cette distribution peut être prédite avec une spline calculée à partir des coordonnées spatiales des observations. Le modèle ne part donc pas du principe que deux observations proches sont plus similaires, mais plutôt qu’il existe un effet spatial permettant de prédire les niveaux moyens de pollution attendus. Un modèle GAM ne vise donc pas explicitement à corriger l’effet de la dépendance spatiale, mais plutôt à capturer un effet spatialement structuré et non capturé par les variables indépendantes \(\mathbf{X}\). Sans l’ajout de la spline, cet effet se serait retrouvé dans les résidus du modèle.
La cartographie de l’effet spatial dans un modèle GAM permet de visualiser les secteurs de l’espace d’étude dans lesquels, toutes choses étant égales par ailleurs, la variable dépendante est plus forte ou plus faible que la moyenne régionale. Cet effet spatial peut être vu comme un ajustement local de la prédiction. Une forme de malus ou de bonus que le modèle ajoute à sa prédiction pour tenir compte de la variation spatiale de la variable dépendante qui n’a pas été expliquée par les variables indépendantes.
Puisqu’un modèle GAM ne prend pas directement en compte l’autocorrélation spatiale, il est tout à fait possible qu’il échoue à réduire suffisamment la dépendance spatiale des résidus d’un modèle global (non spatial). Il faudra alors privilégier d’autres formes de modèles. De même, si notre cadre théorique nous amène à penser que nos observations s’influencent mutuellement dans l’espace, il sera beaucoup plus cohérent d’utiliser un modèle économétrique (chapitre 2).
Prenons un exemple concret pour lequel l’utilisation d’un modèle GAM serait particulièrement pertinente. Dans une étude récente, Gelb et Apparicio (2022) cherchent à modéliser les niveaux d’exposition de cyclistes aux pollutions atmosphériques et sonores. Les données utilisées ont été collectées par des cyclistes qui parcouraient différents environnements urbains équipés de capteurs de bruit et de pollution. Plus spécifiquement, l’objectif de l’étude était de déterminer quelles caractéristiques de l’environnement urbain réduisent ou augmentent significativement les niveaux d’exposition des cyclistes. Dans leur cadre théorique (figure 6.5), les auteurs distinguent :
Les effets du micro-environnement, causés par les caractéristiques locales comme le type de rue utilisé, la densité bâtie, la présence de végétation, etc.
La pollution d’arrière-plan, causée par des phénomènes géographiques régionaux comme la localisation des industries et des autoroutes, la topographie, etc.
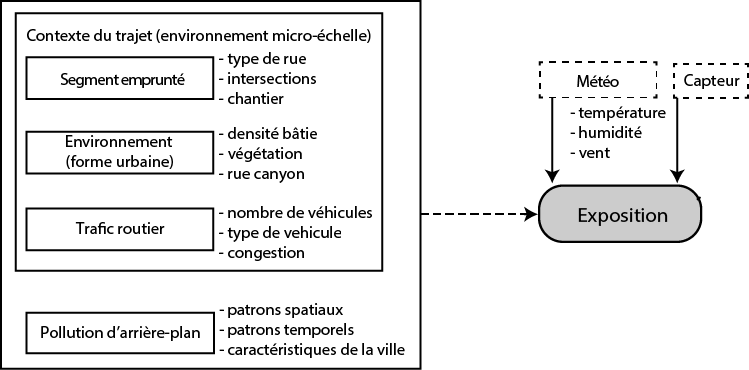
L’exposition mesurée pour un cycliste à un endroit t dépend donc des caractéristiques propres de cet endroit, mais aussi de la pollution d’arrière-plan. Par exemple, si nous prenons une rue A, en tous points identique à une rue B, nous pouvons nous attendre à mesurer des niveaux de pollution plus élevés pour B si celle-ci est située dans un secteur plus industrialisé de la ville. Cette différence ne s’explique pas par des caractéristiques propres à A ou à B, puisqu’elles sont identiques, mais bien par un effet d’arrière-plan produit par différents phénomènes géographiques et donc spatialement autocorrélé. Par conséquent, dans cet exemple, l’intégration de la pollution d’arrière-plan avec une spline spatiale est particulièrement pertinente, car l’interprétation de l’effet produit par cette spline s’intègre directement dans le cadre théorique.
6.4 Markov random field (MRF) ou spline bivariée?
Nous avons vu jusqu’ici qu’il est possible d’incorporer un effet spatial dans un modèle GAM en intégrant une spline bivariée sur les coordonnées spatiales des observations. Cette approche est cependant moins pertinente quand les observations sont des polygones de tailles variées. En effet, intégrer les centroïdes des polygones dans le modèle revient à nettement déformer l’espace de nos données puisque des polygones voisins peuvent avoir des centroïdes très éloignés.
Lorsque les données ont une géométrie irrégulière et que le voisinage est plus important que la proximité (distance), il est recommandé d’utiliser un autre type de fonction appelée un champ de Markov aléatoire (Markov random field, MRF).
Modèle CAR versus GAM avec MRF
Mathématiquement parlant, un modèle de type CAR (conditionnal autoregressive model) est très proche d’un modèle GAM intégrant un MRF puisque la structure spatiale intégrée par un modèle CAR est un MRF : la valeur de la variable dépendante d’une entité est conditionnée par la valeur de ses voisins.
Dans l’équation 6.3, le terme \(\eta\) représente l’effet spatial. Il est le plus souvent modélisé comme un effet provenant d’une distribution normale multivariée, centrée sur zéro et dont la matrice de covariance est calculée grâce à un terme \(\lambda\) et à une matrice de pondération spatiale \(W\). Ce type de modèle est communément appelé un modèle à effet mixte, car il combine des effets fixes (coefficients \(\beta\)) et des effets aléatoires (\(\lambda\)). Les effets aléatoires ne sont pas estimés de la même façon que les effets fixes : ils sont en fait pénalisés. Pour une introduction sur les modèles à effets mixtes, vous pouvez consulter ce chapitre sur les GLMM du livre Méthodes quantitatives en sciences sociales : un grand bol d’R (Apparicio et Gelb 2022).
\[ \begin{aligned} &y \sim D(\mu,\theta)\\ &g(\mu) = \beta_0 + \beta X + \eta \\ &\eta \sim Normal(0,(I - \lambda W)\sigma^2) \end{aligned} \tag{6.3}\]
Il existe un lien direct entre les modèles à effets mixtes et les GAM. En effet, il est possible de reformuler un GLMM comme un GAM et vice-versa, ce qui signifie qu’une spline pénalisée peut être utilisée pour représenter un effet aléatoire (Wood 2017).
Dans R, avec le package mgcv, il est possible d’utiliser une spline pénalisée par une matrice de pondération spatiale W pour approximer l’effet aléatoire que nous aurions modélisé avec un modèle de type CAR. L’intérêt d’utiliser un GAM plutôt qu’un CAR est que nous pouvons contrôler directement le degré de lissage (autocorrélation spatiale) du terme spatial dans le modèle grâce au nombre de degrés de liberté (\(k\)) de la spline. En utilisant un nombre de degrés de liberté maximal (\(k = n-1\)), soit une base par observation, alors nous obtenons un full rank MRF, autorisant de facto la plus grande variance possible du terme spatial. En réduisant \(k\), nous obtenons des modèles d’ordre inférieur (lower rank MRF) dont le terme spatial est plus lisse et moins complexe.
\[ \begin{aligned} &y_i \sim D(\mu_i,\theta)\\ &g(\mu_i) = \beta_0 + \beta X_i + f(W_i) \\ \end{aligned} \tag{6.4}\]
6.5 Mise en œuvre et analyse dans R
Pour illustrer la réalisation des différents modèles GAM (non spatial, avec une spline bivariée sur les coordonnées géographiques et avec une spline spatiale de type MRF), nous utilisons le jeu de données sur les parts modales dans la région métropolitaine de Montréal (section 1.1.2). Ce jeu de données comprend trois variables mesurant respectivement la proportion des individus utilisant la voiture, le transport collectif ou un mode actif (marche ou vélo) comme mode de transport principal pour leurs déplacements domicile-travail en 2021 pour les secteurs de recensement (figure 1.2).
Lorsqu’un ensemble de variables sont des proportions d’un total (leur somme donne 1 ou 100), alors l’ensemble de ces variables est désigné comme des données compositionnelles. Ces données doivent être analysées avec des méthodes spécifiques, car elles ont un comportement particulier. La diminution de l’une d’entre elles provoque nécessairement l’augmentation d’une autre. Elles ne sont donc pas indépendantes et certaines catégories ont même tendance à exister simultanément ou au contraire à se repousser. L’analyse de données compositionnelles est un domaine en soit et sort du matériel que nous souhaitons couvrir dans ce livre. Il existe d’excellentes ressources et packages R sur le sujet (Boogaart et Tolosana-Delgado 2013; van den Boogaart, Tolosana-Delgado et Bren 2024; Tsagris et Athineou 2025).
Nous utilisons ici l’approche du log des ratios (alr). Il s’agit d’une transformation qui peut être appliquée aux données compositionnelles pour pouvoir les analyser avec des méthodes classiques de statistiques. Une autre méthode de transformation est habituellement privilégié, soit celle isométrique des log ratios (ilr), mais cette dernière produit des résultats plus difficiles à interpréter (Greenacre, Martinez-Alvaro et Blasco 2021). Nous utiliserons donc l’approche alr dans cet exemple. La transformation alr est décrite par la formule suivante :
\[ \operatorname{alr}(x)=\left[\log \frac{x_1}{x_D}, \cdots, \log \frac{x_{D-1}}{x_D}\right] \tag{6.5}\]
Pour une variable compositionnelle x comprenant D dimensions (catégories), la transformation alr consiste à calculer D-1 log de ratio entre les différentes dimensions D et une référence parmi D. Ainsi, le nombre de dimensions de la version transformée de x est toujours de D-1.
Dans cet exemple, nous utilisons le ratio entre les personnes utilisatrices du transport collectif (TC) et de l’automobile. Puisque la transformation alr implique une division, puis un log, il est important que ni le numérateur ni le dénominateur ne soit égal à 0. Or, nous avons quelques secteurs de recensement (SR) avec des parts modales TC à 0. Puisqu’il semble peu probable qu’aucune personne dans un SR n’utilise le transport collectif, nous remplaçons les 0 par le plus faible pourcentage trouvé dans les SR avec la valeur supérieure à 0.
library(sf, quietly = TRUE)
library(ggplot2, quietly = TRUE)
library(tmap, quietly = TRUE)
library(dplyr, quietly = TRUE)
library(ggpubr, quietly = TRUE)
# Chargement des données
load("data/Mtl.Rdata")
# Nous préparons ici les données en calculant les ratios
# remplaçant les 0 et calculant la transformation alr
data_mtl <- data_mtl %>%
mutate(
prt_tc = ifelse(prt_tc == 0, min(prt_tc[prt_tc>0]) ,prt_tc)
) %>%
mutate(
ratio = (prt_tc / prt_auto),
alr_val = log(prt_tc / prt_auto)
)
plot1 <- ggplot(data_mtl) +
geom_histogram(aes(x = ratio), fill = 'grey', color = 'black', bins = 30) +
theme_bw() +
labs(x = 'part modale TC / part modale auto',
y = 'effectif'
)
plot2 <- ggplot(data_mtl) +
geom_histogram(aes(x = alr_val), fill = 'grey', color = 'black', bins = 30) +
theme_bw() +
labs(x = 'log(part modale TC / part modale auto)',
y = 'effectif'
)
ggarrange(plot1, plot2, nrow = 2)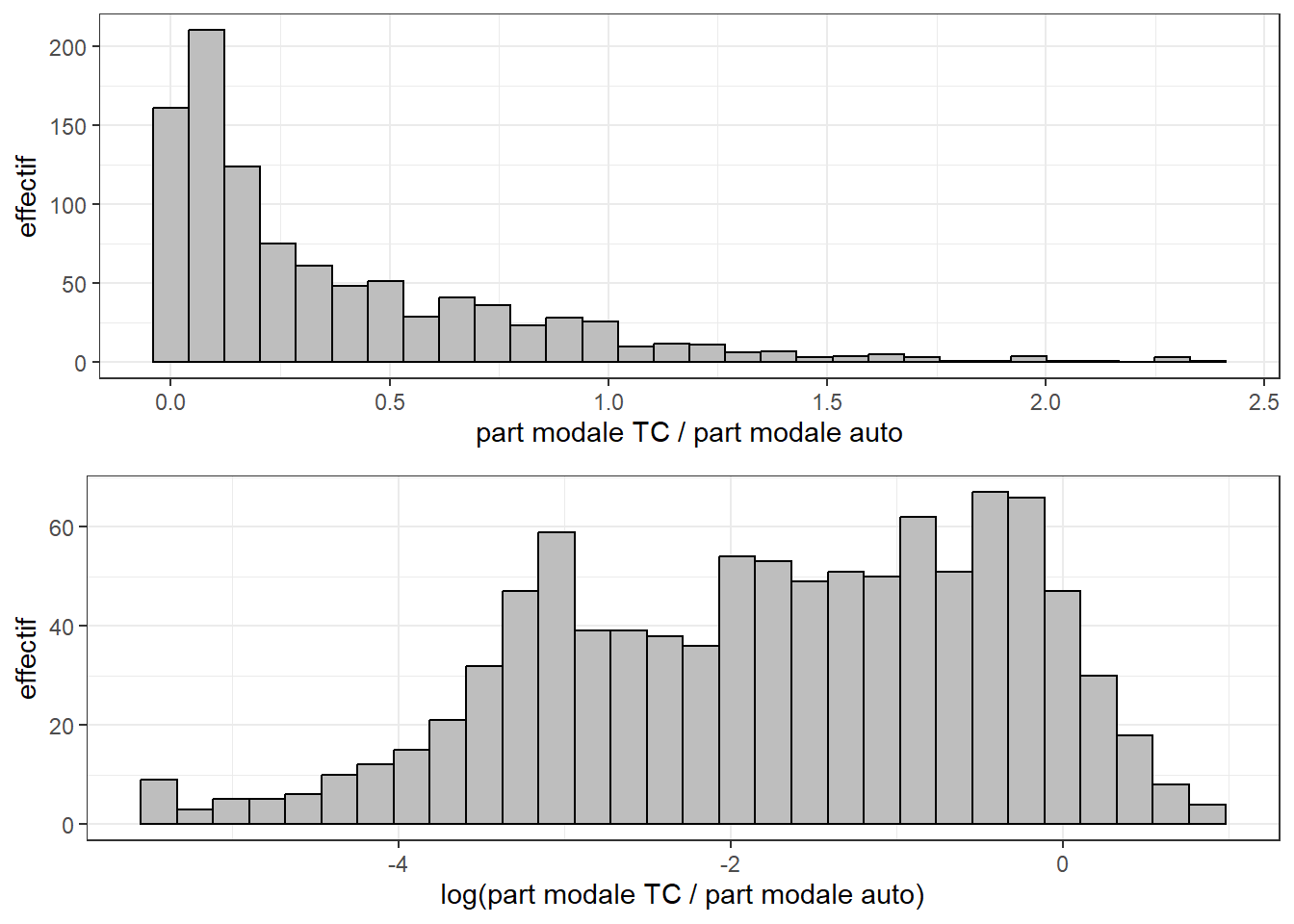
La figure 6.6 illustre la distribution de la variable que nous souhaitons modéliser. Le simple ratio a des valeurs comprises entre 0 et 2,5. Une valeur de 0 signifie que personne dans le secteur de recensement n’utilise le transport collectif comme mode principal pour ses déplacements pendulaires. Une valeur de 1 indique que cette proportion est égale à celle des personnes utilisant la voiture. Une valeur plus grande que 1 indique une dominance du mode TC plutôt que de l’automobile. Sans surprise, pour la majorité des secteurs de recensement, la valeur est inférieure à 1. Le log du ratio suit une distribution moins asymétrique qui sera probablement plus facile à modéliser.
library(spdep, quietly = TRUE)
library(dplyr, quietly = TRUE)
# Matrice de de contiguïté selon le partage d'un nœud
queen_nb <- poly2nb(data_mtl, queen = TRUE)
queen_w <- nb2listw(queen_nb, style = 'W', zero.policy = TRUE)
# Calcul du I de moran de la variable ratio
moran_i <- moran.mc(data_mtl$alr_val,
listw = queen_w,
zero.policy = TRUE, nsim = 999)
# Texte pour la valeur du I de Moran
moran_text <- format(as.numeric(round(moran_i$statistic,3)) , decimal.mark =",")
# Cartographie de la variable
legende_parametres <- list(text.separator = "à",
decimal.mark = ",",
big.mark = " ",
digits = 2)
tmap_mode("plot")
tm_shape(data_mtl)+
tm_polygons(
col = NULL,
fill = "alr_val",
fill.scale = tm_scale_intervals(
n = 7,
midpoint = log(1),
style = "jenks",
values = "-brewer.rd_bu",
label.format = legende_parametres
),
fill.legend = tm_legend(
title = "part modale TC / part modale auto",
frame = FALSE,
position = tm_pos_out("right", pos.v = "center")
)
) +
tm_layout(frame = FALSE) +
tm_scale_bar(breaks = c(0,10),
position = tm_pos_out("right", pos.v = "bottom")
) +
tm_credits(paste0('I de Moran = ', moran_text,
" (matrice de contiguïté selon le partage d’un nœud)."),
position = tm_pos_out("center", "bottom")
)
Sans surprise, notre variable dépendante est fortement spatialement autocorrélée. Plus un secteur est éloigné du centre-ville, plus le transport collectif est délaissé au profit de la voiture. Les secteurs dans lesquels la part modale du TC est supérieure à celle de l’automobile sont situés au centre de l’île de Montréal, à proximité des lignes de métro.
6.5.1 Modèles GAM sans intégration de l’espace
Pour modéliser cette variable, nous utilisons deux ensembles de variables indépendantes extraites du recensement de 2021 de Statistique Canada pour les secteurs de recensement de la région métropolitaine de Montréal :
- Des variables sociodémographiques :
- Pourcentage de personnes issues des minorités visibles (
prt_minorite_vis). - Pourcentage de ménages monoparentaux (
prt_monoparental). - Taux de chômage (
prt_chomage). - Revenu médian des ménages en milliers de dollars (
revenu_median). - Pourcentage de personnes à faible revenu (
prt_personnes_faibles_revenu).
- Des variables mesurant les niveaux d’accessibilité :
- Niveau d’accessibilité aux emplois en heure de pointe en transport collectif (
acs_idx_emp_tc_peak). - Niveau d’accessibilité aux emplois à pied : (
acs_idx_emp_pieton).
Les indicateurs d’accessibilité sont exprimés comme un score variant de 0 (pire accessibilité au Canada) à 1 (meilleure accessibilité au Canada). Ils servent à capturer la mesure dans laquelle le transport collectif ou la marche permet d’atteindre des emplois (lieux d’activités et de consommation). Dans ce modèle relativement simple, nous nous attendons à ce que des secteurs avec des populations plus vulnérables (variables sociodémographiques) présentent une part modale du transport collectif plus élevée que celle de l’automobile (dépendance au TC). Nous souhaitons cependant vérifier si cette relation tient toujours une fois que nous prenons en considération la performance du transport collectif et la possibilité d’atteindre des activités à pied.
library(mgcv)
library(car)
# Vérification de la multicolinéarité avant d’ajuster un premier modèle
vif(lm(alr_val ~ prt_minorite_vis + prt_monoparental +
prt_chomage + revenu_median + prt_personnes_faibles_revenu +
acs_idx_emp_tc_peak + acs_idx_emp_pieton,
data = data_mtl
)) prt_minorite_vis prt_monoparental
1.892323 1.750261
prt_chomage revenu_median
3.007752 2.227562
prt_personnes_faibles_revenu acs_idx_emp_tc_peak
5.343381 2.977366
acs_idx_emp_pieton
2.760775 Les valeurs du facteur d’inflation de la variance (VIF) sont relativement faibles, excepté celle du pourcentage de personne à faible revenu qui dépasse 5. Par conséquent, nous décidons de la retirer du modèle.
Nous commençons par ajuster un simple GLM (non spatial), assumant une distribution normale de la variable dépendante, une fois contrôlées les variables indépendantes (family = gaussian). Pour valider les résidus de ce modèle, nous utilisons la méthode des résidus simulés.
Les résidus simulés
Pour une description des résidus simulés, vous pourrez consulter ce chapitre sur les GLM du livre Méthodes quantitatives en sciences sociales : un grand bol d’R (Apparicio et Gelb 2022).
library(DHARMa)
library(mgcViz)
# Modèle GLM avec une distribution normale
glm_base <- gam(alr_val ~ prt_minorite_vis + prt_monoparental + revenu_median +
acs_idx_emp_tc_peak + acs_idx_emp_pieton,
data = data_mtl,
family = gaussian)
# Validation des résidus
res <- simulateResiduals(glm_base, plot = FALSE)
plot(res)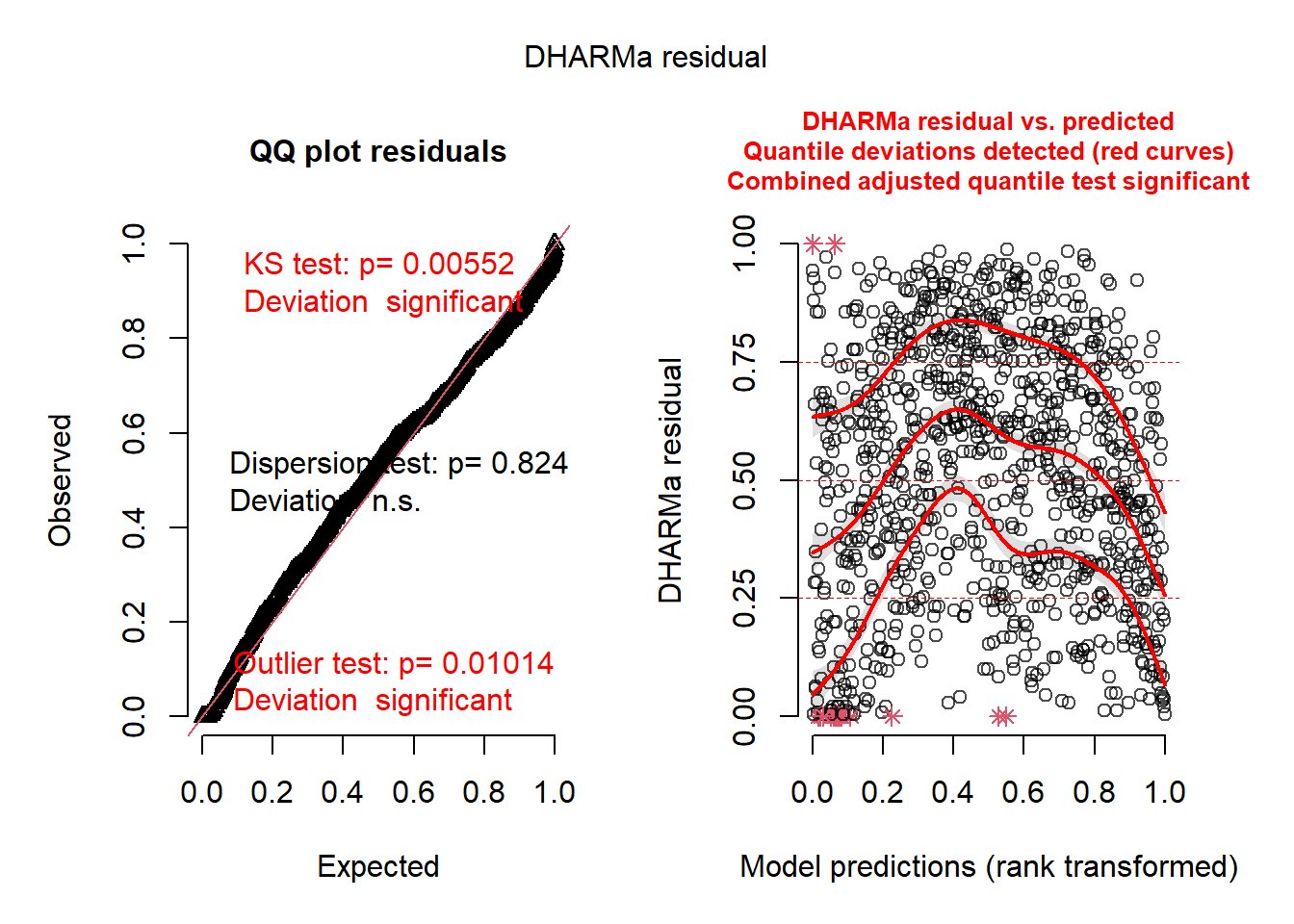
La figure 6.8 indique que les résidus simulés ne suivent pas vraiment une distribution uniforme et sont marqués par des valeurs extrêmes. Pour améliorer ce premier modèle, nous utilisons une distribution de Student (family = scat). Cette dernière ressemble beaucoup à la distribution normale, mais admet davantage de valeurs extrêmes. Autrement dit, elle permet donc de réduire l’impact des valeurs extrêmes dans le modèle.
# Modèle GLM avec une distribution normale de Student
glm_base <- gam(alr_val ~ prt_minorite_vis + prt_monoparental + revenu_median +
acs_idx_emp_tc_peak + acs_idx_emp_pieton,
data = data_mtl,
family = scat)
# Validation des résidus
res <- simulateResiduals(glm_base, plot = FALSE)
plot(res)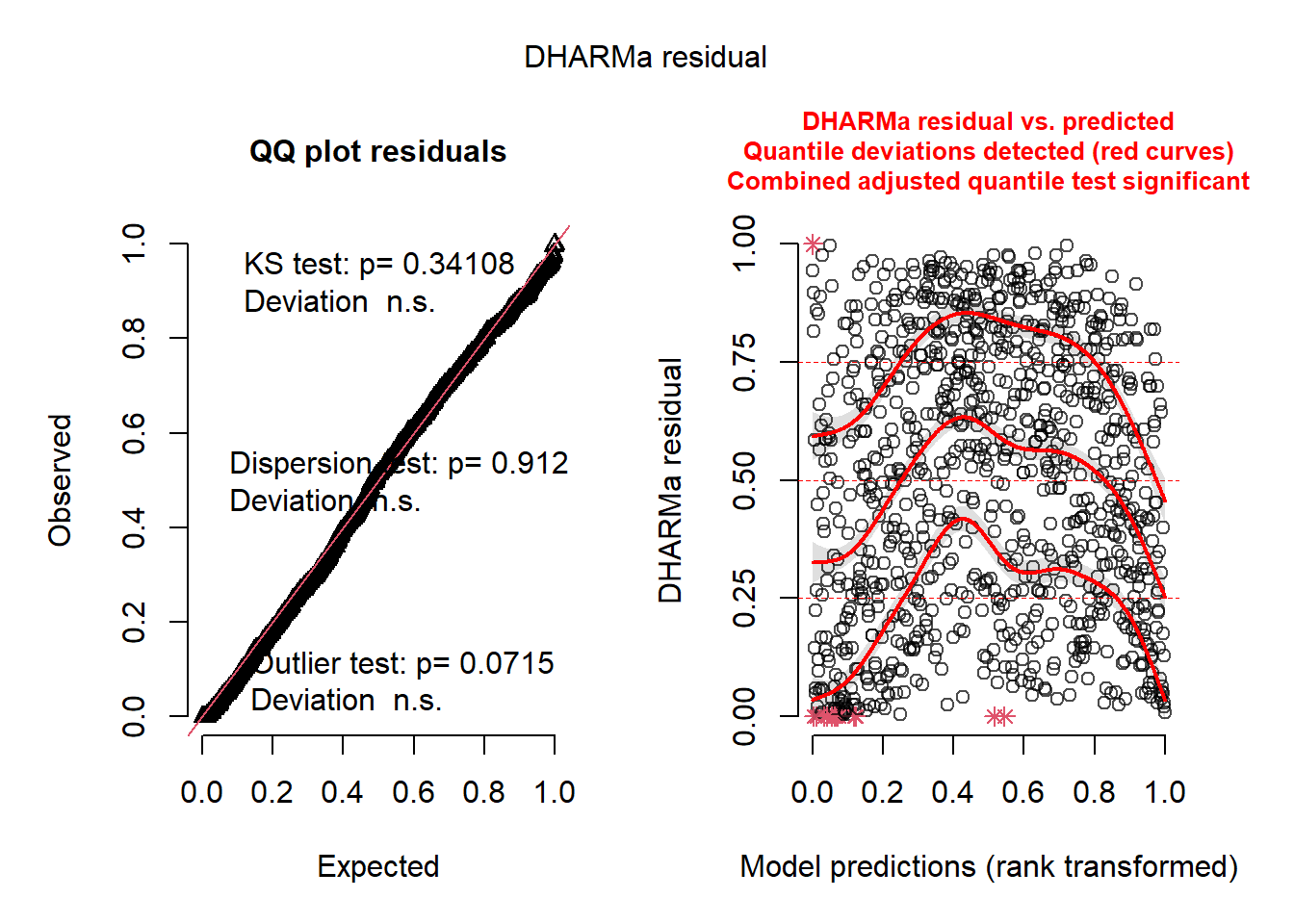
Une nette amélioration est observable à la figure 6.9, bien que les quantiles des résidus tendent encore à dévier des valeurs attendues. Plusieurs raisons pourraient expliquer cette situation, mais il est fort probable qu’elle soit provoquée par l’autocorrélation spatiale dans les résidus.
# I de Moran des résidus des deux modèles (gaussien et Student)
moran.mc(residuals(glm_base, type = 'pearson'),
listw = queen_w, nsim = 999,
zero.policy = TRUE)
Monte-Carlo simulation of Moran I
data: residuals(glm_base, type = "pearson")
weights: queen_w
number of simulations + 1: 1000
statistic = 0.52098, observed rank = 1000, p-value = 0.001
alternative hypothesis: greatermoran_i <- moran.mc(residuals(res),
listw = queen_w, nsim = 999,
zero.policy = TRUE)
print(moran_i)
Monte-Carlo simulation of Moran I
data: residuals(res)
weights: queen_w
number of simulations + 1: 1000
statistic = 0.54085, observed rank = 1000, p-value = 0.001
alternative hypothesis: greatermoran_text <- format(as.numeric(round(moran_i$statistic,3)),
decimal.mark =",")
data_mtl$base_residual <- residuals(glm_base, type = 'response')
# Cartographie
tmap_mode("plot")
tm_shape(data_mtl)+
tm_polygons(
col = NULL,
fill = "base_residual",
fill.scale = tm_scale_intervals(
n = 7,
midpoint = 0,
style = "jenks",
values = "-brewer.rd_bu",
label.format = legende_parametres
),
fill.legend = tm_legend(
title = "Résidus simulés",
frame = FALSE,
position = tm_pos_out("right", pos.v = "center")
)
) +
tm_layout(frame = FALSE) +
tm_scale_bar(breaks = c(0,10),
position = tm_pos_out("right", pos.v = "bottom")
) +
tm_credits(paste0('I de Moran = ', moran_text,
" (matrice de contiguïté selon le partage d’un nœud)."),
position = tm_pos_out("center", "bottom")
)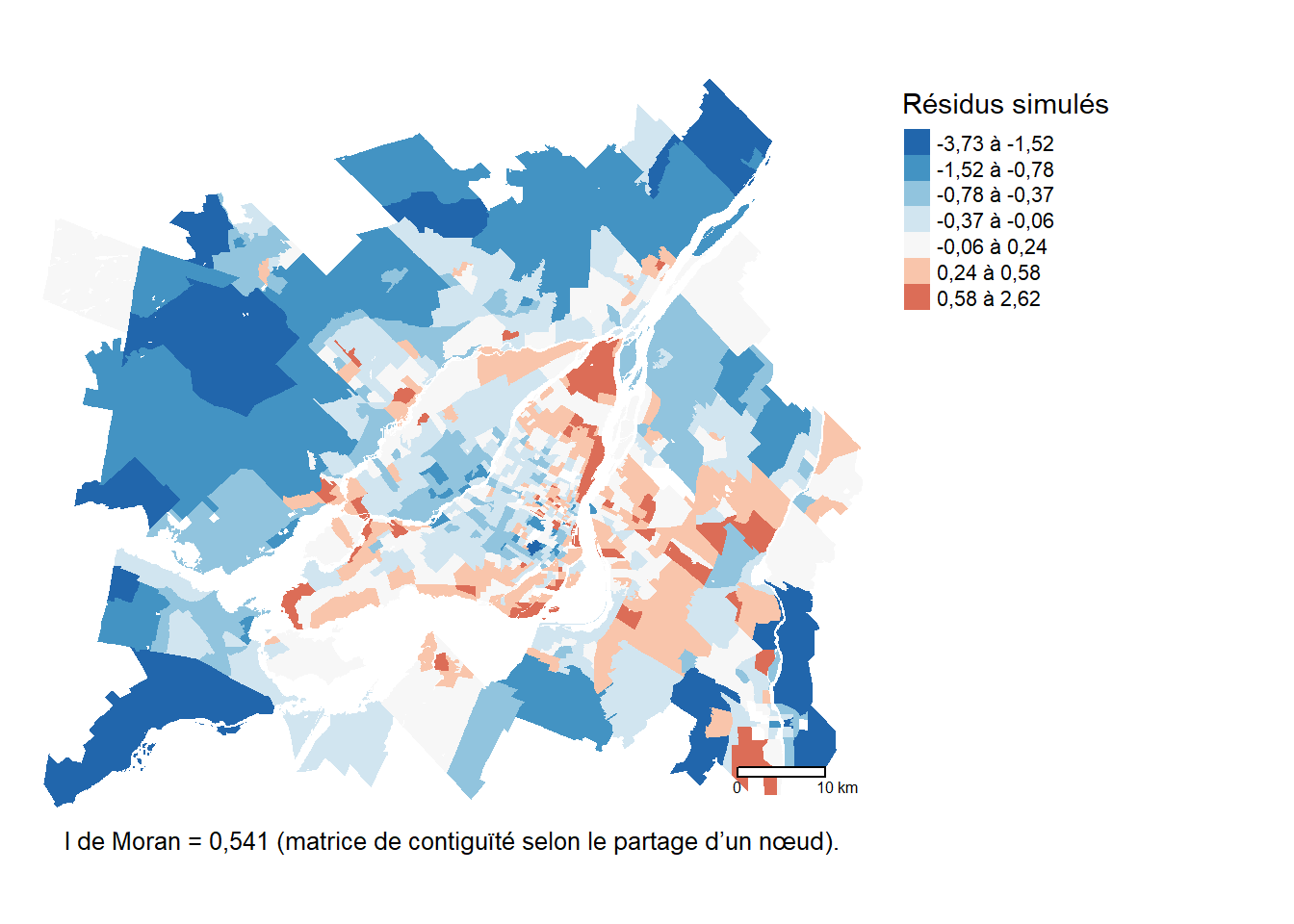
En effet, la figure 6.10 démontre clairement que la distribution des résidus du modèle GLM (avec une distribution de Student) n’est pas aléatoire spatialement. Les valeurs négatives indiquent des secteurs dans lesquels le modèle tend à prédire un log ratio trop favorable au transport collectif et inversement dans les secteurs avec des valeurs positives.
6.5.2 GAM avec spline spatiale bivariée sur les coordonnées géographiques
Nous ajustons ici un modèle GAM en y intégrant une spline bivariée sur les coordonnées des centroïdes des secteurs de recensement. Le rôle de cette spline est de capturer une tendance spatiale à l’utilisation plus ou moins prononcée du transport collectif. Cet effet correspond à l’agrégat d’un ensemble de variables que nous n’avons pas pu mesurer, par exemple la revendication écologique, la difficulté de stationner une voiture, la présence d’autres modes de déplacement durables connecté au transport en commun, la démographie, etc. Notons ici que nous utilisons une spline de type processus gaussien (bs = 'gp', m = 3) avec une structure de covariance Matérn qui est communément utilisée en géostatistique pour le krigeage.
# Coordonnées X et Y
XY <- st_coordinates(st_centroid(data_mtl))
data_mtl$X <- XY[,1]
data_mtl$Y <- XY[,2]
# Modèle GAM avec une spline bivariée sur les coordonnées géographiques
gam1 <- gam(alr_val ~ prt_minorite_vis + prt_monoparental + revenu_median +
acs_idx_emp_tc_peak + acs_idx_emp_pieton +
s(X,Y, bs = 'gp', m = 3),
data = data_mtl,
family = scat)
# Résidus du modèle
res <- simulateResiduals(gam1, plot = FALSE)
plot(res)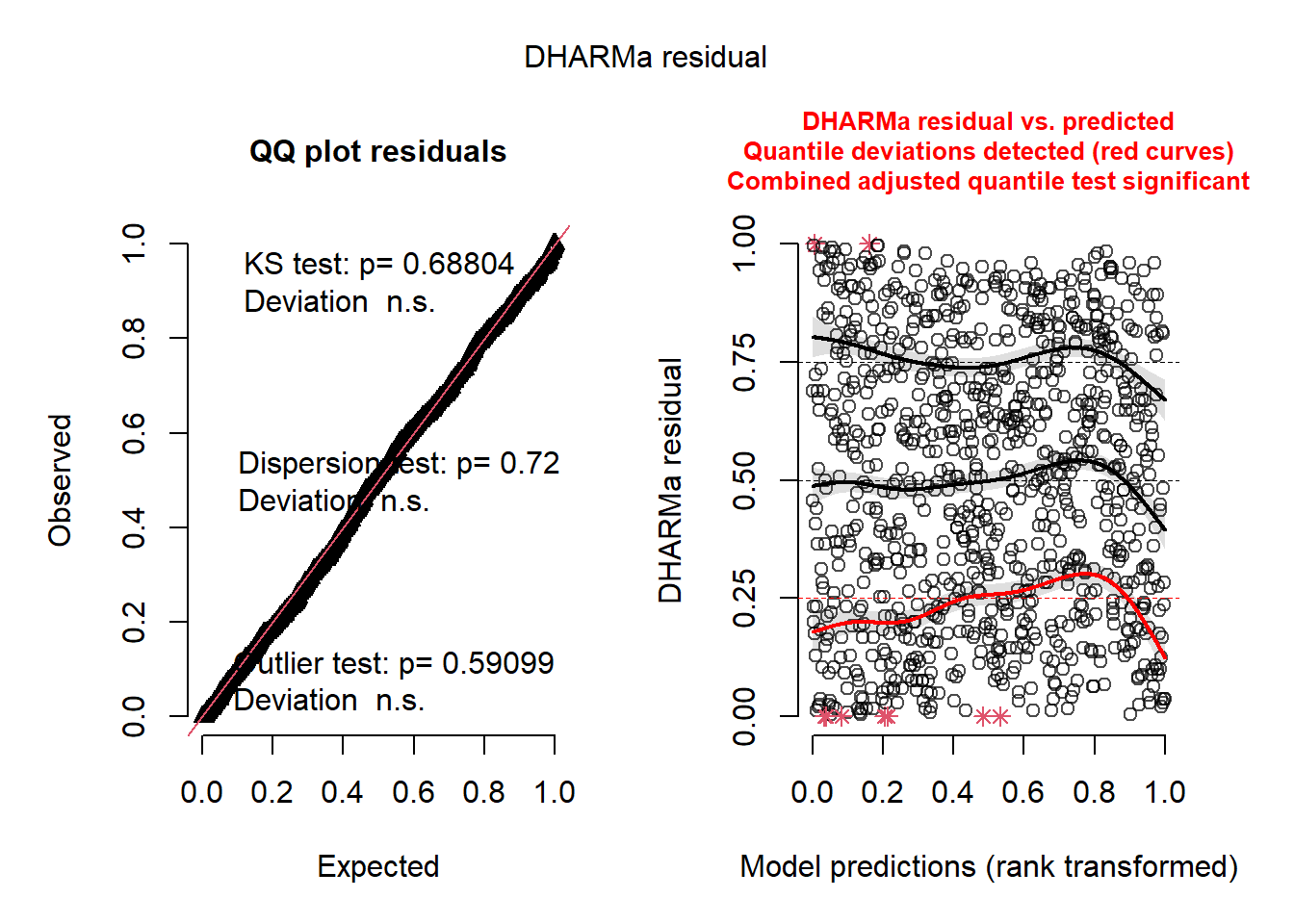
Les résidus simulés de ce nouveau modèle se comportent bien mieux que les résidus que nous avions obtenus pour les deux modèle GLM n’intégrant pas l’espace (figure 6.11). Nous pouvons maintenant nous pencher sur l’autocorrélation spatiale des résidus simulés qui devraient suivre une distribution uniforme et aléatoire spatialement.
data_mtl$sim_residual <- residuals(res)
test <- moran.mc(data_mtl$sim_residual, listw = queen_w, nsim = 999, zero.policy = TRUE)
print(test)
Monte-Carlo simulation of Moran I
data: data_mtl$sim_residual
weights: queen_w
number of simulations + 1: 1000
statistic = 0.30525, observed rank = 1000, p-value = 0.001
alternative hypothesis: greatermoran_text <- format(as.numeric(round(test$statistic, 3)),
decimal.mark =",")
tm_shape(data_mtl)+
tm_polygons(
col = NULL,
fill = "sim_residual",
fill.scale = tm_scale_intervals(
n = 7,
midpoint = 0.5,
style = "jenks",
values = "-brewer.rd_bu",
label.format = legende_parametres
),
fill.legend = tm_legend(
title = "Résidus simulés",
frame = FALSE,
position = tm_pos_out("right", pos.v = "center")
)
) +
tm_layout(frame = FALSE) +
tm_scale_bar(breaks = c(0,10),
position = tm_pos_out("right", pos.v = "bottom")
) +
tm_credits(paste0('I de Moran = ', moran_text,
" (matrice de contiguïté selon le partage d’un nœud)."),
position = tm_pos_out("center", "bottom")
)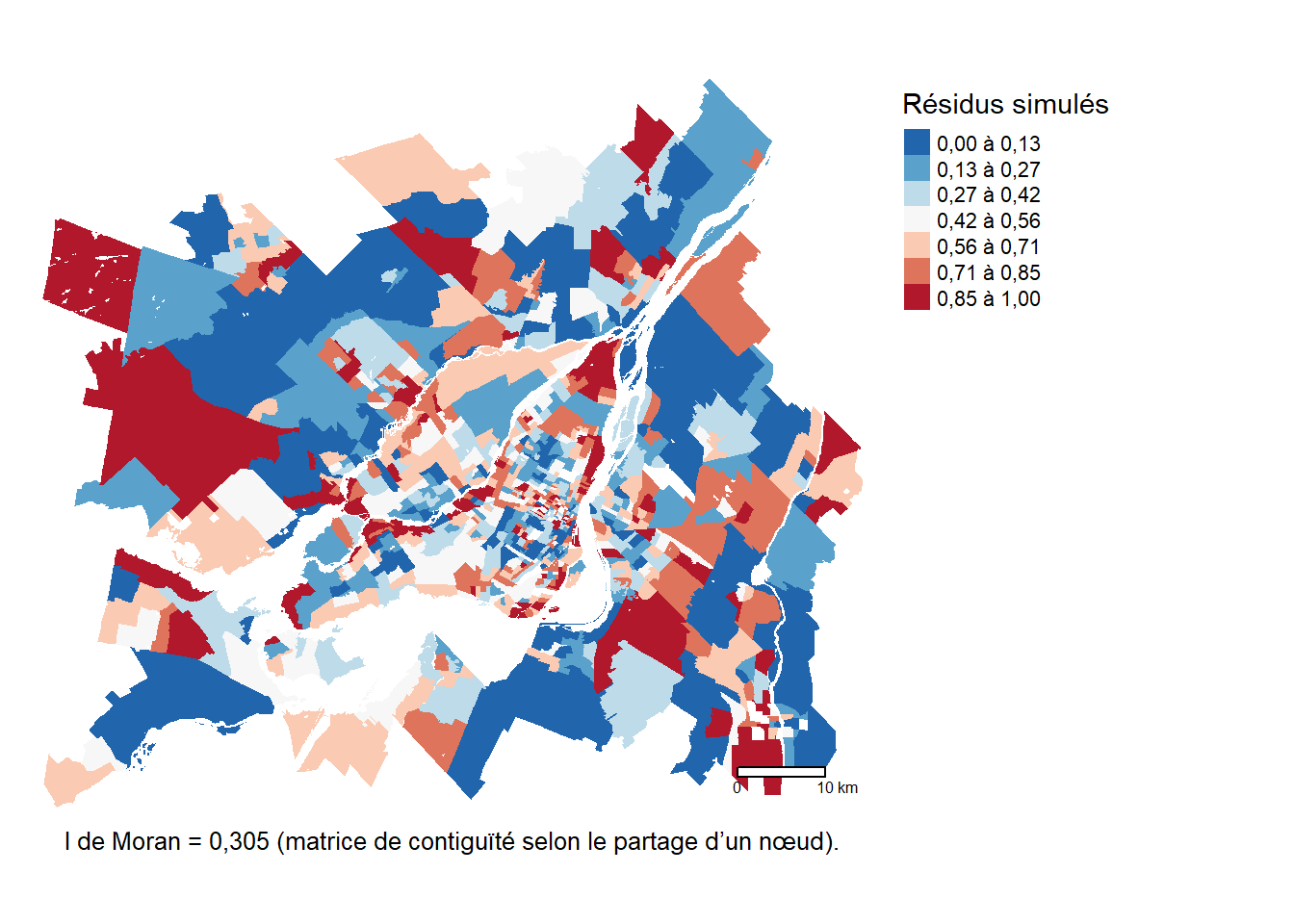
La valeur du I de Moran (I = 0,305), calculée à partir de la matrice de contiguïté selon le partage d’un nœud (Queen), indique toujours une autocorrélation spatiale non négligeable des résidus (figure 6.12).
Toutefois, le modèle GAM n’est pas basé sur les relations de voisinage entre les observations (contiguïté), mais sur la localisation de leurs centroïdes (proximité) pour estimer le terme spatial. Dans ce contexte, il serait plus judicieux d’évaluer l’autocorrélation des résidus du modèle en utilisant une matrice de pondération spatiale basée sur l’inverse des distances.
dists <- 1/as.matrix(dist(XY))
diag(dists) <- 0
dist_w <- mat2listw(dists)
moran.mc(data_mtl$sim_residual, listw = dist_w, nsim = 999)
Monte-Carlo simulation of Moran I
data: data_mtl$sim_residual
weights: dist_w
number of simulations + 1: 1000
statistic = 0.025581, observed rank = 1000, p-value = 0.001
alternative hypothesis: greaterNous constatons alors que le modèle est parvenu à retirer l’autocorrélation spatiale des résidus (I de Moran de 0,026), si elle est évaluée avec la façon dont l’espace est pris en compte dans le modèle. Interprétons maintenant les résultats du modèle avec la fonction summary.
results <- summary(gam1)
print(results)
Family: Scaled t(4.458,0.307)
Link function: identity
Formula:
alr_val ~ prt_minorite_vis + prt_monoparental + revenu_median +
acs_idx_emp_tc_peak + acs_idx_emp_pieton + s(X, Y, bs = "gp",
m = 3)
Parametric coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -2.646739 0.121130 -21.850 < 2e-16 ***
prt_minorite_vis 0.876472 0.100188 8.748 < 2e-16 ***
prt_monoparental 1.398126 0.277368 5.041 4.64e-07 ***
revenu_median -0.010175 0.001691 -6.017 1.78e-09 ***
acs_idx_emp_tc_peak 3.936414 0.187545 20.989 < 2e-16 ***
acs_idx_emp_pieton -1.548512 0.177466 -8.726 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Approximate significance of smooth terms:
edf Ref.df Chi.sq p-value
s(X,Y) 26.81 28.9 941.5 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
R-sq.(adj) = 0.902 Deviance explained = 81.4%
-REML = 543.3 Scale est. = 1 n = 986Le R2 ajusté est très élevé (0,902), indiquant que le modèle est capable d’expliquer une part significative de la déviance de nos données. Chacune des variables explicatives a un impact significatif sur le ratio entre les parts modales de TC et de l’automobile. Pour interpréter leurs effets, nous devons tenir compte de l’impact de la transformation alr. Pour rappel, notre modèle prédit la moyenne de notre logarithme du ratio entre la part TC et la part automobile. Il est possible de passer de l’échelle logarithme à l’échelle naturelle en utilisant la fonction exponentielle (exp). Si nous transformons les coefficients obtenus avec la fonction exp, alors ils expriment l’impact multiplicatif des variables indépendantes sur le ratio entre la part TC et la part automobile. Si ce ratio augmente, c’est que l’automobile est moins utilisée et/ou que le TC est plus utilisé et inversement.
| Variable | Coefficient | exp(coefficent) | Valeur de p |
|---|---|---|---|
| Constante | -2,647 | 0,071 | 0 |
| prt_minorite_vis | 0,876 | 2,402 | 0 |
| prt_monoparental | 1,398 | 4,048 | 0 |
| revenu_median | -0,010 | 0,990 | 0 |
| acs_idx_emp_tc_peak | 3,936 | 51,235 | 0 |
| acs_idx_emp_pieton | -1,549 | 0,213 | 0 |
| R2 ajusté = 0,9021. |
Voici une interprétation des effets obtenus (tableau 6.1) :
Comparativement à un SR avec 0 % de personnes issues des minorités visibles, un SR avec 25 % de ce groupe de la population verrait augmenter la moyenne du log du ratio de \(0,876 \times 0,25 = 0,219\), ce qui correspond à une multiplication par 1,245 du ratio, ou encore à une augmentation de 24,5 % du ratio. Il semblerait donc que toutes choses étant égales par ailleurs, la concentration des minorités visibles soit associée à une plus grande proportion d’utilisation du TC et inversement, à une plus faible utilisation de la voiture.
Comparativement à un SR avec 0 % de ménages monoparentaux, un SR avec 25 % de ce groupe de la population verrait augmenter la moyenne du log du ratio de \(1,398 \times 0,25 = 0,3495\), ce qui correspond à une multiplication par 1,418 du ratio, ou encore à une augmentation de 41,8 % du ratio. Il semblerait donc que toutes choses étant égales par ailleurs, la concentration des ménages monoparentaux soit associée à une plus grande proportion d’utilisation du TC et inversement, à une plus faible utilisation de la voiture.
Lorsque le revenu médian dans un SR augmente de 1000 dollars, nous observons une réduction de la moyenne du log du ratio de -0,01, soit une multiplication du ratio par 0,99. En d’autres termes, le ratio diminue de 1 % à chaque millier de dollars supplémentaire. Il semblerait donc que dans les SR les plus nantis, l’utilisation du TC soit plus délaissée au profit de la voiture.
Lorsque l’accessibilité aux emplois en transport collectif est plus élevée, la moyenne du log du ratio augmente. Dans un SR avec le pire niveau d’accessibilité possible, augmenter l’accessibilité au niveau du premier quartile (au moins mieux que 25% des SR) serait associé à une augmentation de la moyenne du log du ratio de \(3,936 \times 0,25 = 0,984\), ce qui correspond à une multiplication par 2,675 du ratio.
Cependant, lorsque l’accessibilité à pied augmente, nous observons une réduction de la moyenne du log du ratio. Dans un SR avec le pire niveau d’accessibilité possible, augmenter l’accessibilité au niveau du premier quartile (au moins mieux que 25 % des SR) serait associé à une augmentation de la moyenne du log du ratio de \(-1,549 \times 0,25 = -0,387\), ce qui correspond à une multiplication par 0,679 du ratio, ou encore à une réduction de 32,1 %. Ce résultat s’explique vraisemblablement par l’utilisation des modes de transport actifs plutôt que par une utilisation accrue de la voiture.
Dans le résumé du modèle, nous pouvons observer que la spline utilisée pour capturer l’effet spatial à un impact significativement différent de 0 et comporte environ 27 degrés de liberté. Afin d’observer l’effet de cette spline, nous utilisons l’approche des effets marginaux. Cette approche consiste à effectuer une prédiction avec le modèle de la valeur attendue de la variable dépendante en conservant identiques toutes les variables indépendantes, sauf la localisation dans l’espace. En d’autres termes, nous essayons de voir comment le modèle s’ajuste lorsqu’il doit prédire la valeur Y pour une observation spécifique, mais que celle-ci est déplacée dans l’espace. Ainsi, la variation de la prédiction est affectée uniquement par l’espace.
Pour obtenir l’effet uniquement spatial, nous pouvons mettre arbitrairement toutes les valeurs à 0 des différentes variables indépendantes du modèle. Ainsi, même multipliées par leurs coefficients, leur contribution dans la prédiction restera 0. Il suffit ensuite de retirer la constante pour ne conserver que l’effet de la spline.
#' Nous commençons par construire un dataframe de prédictions. Toutes les
#' variables indépendantes sont fixées à 0 et nous allons
#' prédire les valeurs tous les 500 m
bbox <- st_bbox(data_mtl)
df_pred <- expand.grid(
prt_minorite_vis = 0,
prt_monoparental = 0,
revenu_median = 0,
acs_idx_emp_tc_peak = 0,
acs_idx_emp_pieton = 0,
X = seq(bbox[[1]], bbox[[3]], 500),
Y = seq(bbox[[2]], bbox[[4]], 500)
)
# Nous effectuons ensuite la prédiction sur le prédicteur linéaire
df_pred$pred_log <- predict.gam(gam1, newdata = df_pred, type = 'link')
# Nous retirons ensuite la constante pour ne garder que l’effet spatial
df_pred$pred_log_cent <- df_pred$pred_log - gam1$coefficients[[1]]
# Nous pouvons ensuite utiliser la fonction exp pour faciliter l’interprétation
# puisque le ratio sera plus facile à lire que le log ratio
df_pred$pred_exp <- exp(df_pred$pred_log_cent)
# Il ne reste ensuite qu’à cartographier notre effet spatial
sf_pred <- df_pred %>%
st_as_sf(coords = c('X', 'Y'), crs = st_crs(data_mtl)) %>%
subset(lengths(st_intersects(.,data_mtl)) > 0)
tmap_mode("plot")
map_spline <- tm_shape(sf_pred)+
tm_dots(
fill = "pred_exp",
fill.scale = tm_scale_intervals(
style = "fisher",
n = 7,
midpoint = 1,
values = "-brewer.rd_bu",
label.format = legende_parametres
),
fill.legend = tm_legend(
title = paste0("effet de la \nspline bivariée\n(edf = ",
round(results$edf), ")"),
frame = FALSE,
position = tm_pos_out("right", pos.v = "center")
)
) +
tm_shape(data_mtl) +
tm_borders('darkgrey', lwd = 0.01) +
tm_layout(frame = FALSE) +
tm_scale_bar(breaks = c(0,10),
position = tm_pos_out("right", pos.v = "bottom")
)
map_spline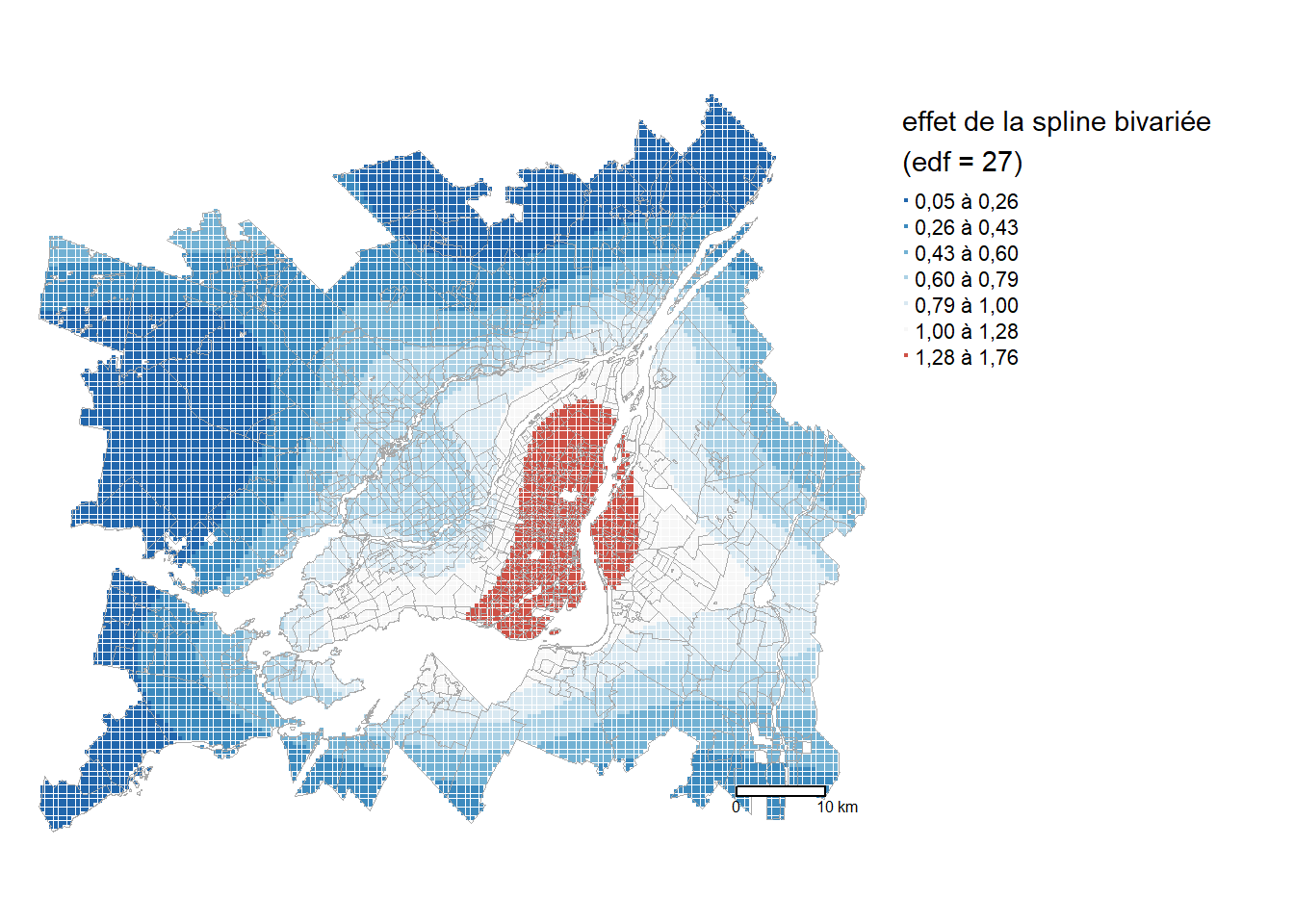
La figure 6.13 permet de visualiser l’effet multiplicatif de la spline spatiale sur le ratio prédit par le modèle. Ainsi, toute chose étant égale par ailleurs, le ratio de part modale TC/auto est de 30 % à 70 % plus fort dans les quartiers centraux de Montréal, allant de Lachine à Anjou. L’extrémité ouest de Longueuil fait aussi partie de cette zone avec le bonus spatial le plus important. Aussi, on constate que l’effet spatial diminue avec la distance au centre-ville. Pour la majeure partie de Laval, le ratio est réduit de près de 50 %.
6.5.3 GAM avec spline spatiale de type MRF
Puisque nos observations sont des polygones, utiliser leurs centroïdes pour représenter l’espace est une approximation maladroite. Nous allons donc opter pour un Markov random field afin de modéliser les variations spatiales en fonction du voisinage.
L’enjeu avec ce type de modèle est de sélectionner son rang (\(k\)). Pour cela, nous testons plusieurs valeurs allant de 10 à 250 autorisant une complexité grandissante du terme spatial. Notons d’emblée que notre spline bivariée précédente avait nécessité seulement 25 degrés de liberté supplémentaires. La sélection de \(k\) (le nombre de degrés de liberté accordé au MRF) reposera sur deux critères : l’autocorrélation spatiale encore présente dans les résidus (I de Moran calculé sur les résidus de Pearson) et l’AIC (pénalisant la complexité des modèles).
Pour accélérer le calcul, nous réalisons cette opération en traitement parallèle (multiprocessing). Quatre cœurs indépendants s’occuperont d’ajuster les différents modèles.
# Package pour le traitement en parallèle
library(future)
library(future.apply)
# nous préparons les informations de voisinage pour le terme MRF
nb <- poly2nb(data_mtl)
names(nb) <- as.integer(attr(nb, "region.id"))
data_mtl$ID_LOC <- as.integer(attr(nb, "region.id"))
ks <- seq(10,250,20)
# nous allons itérer sur les valeurs de ks et ajuster nos modèles
# nous récupérons à chaque fois les informations pertinentes dans nos
# résidus
S0 <- sum(sapply(queen_w$weights, sum))
future::plan(future::multisession(workers = 4))
resultats <- future_sapply(ks, function(k){
model <- gam(alr_val ~ prt_minorite_vis + prt_monoparental + revenu_median +
acs_idx_emp_tc_peak + acs_idx_emp_pieton +
s(ID_LOC, bs = 'mrf', xt = list(nb = nb), k = k),
data = data_mtl, family = scat)
resid <- residuals.gam(model, type = 'scaled.pearson')
I <- moran(resid, queen_w, n = length(resid), S0 = S0, zero.policy = TRUE)
aic_score <- AIC(model)
return(c(I[[1]],aic_score,k))
})
df_plot <- data.frame(t(resultats))
names(df_plot) <- c('moranI', 'aic', 'k')# Graphique pour le I de Moran
plot1 <- ggplot(df_plot) +
geom_line(aes(x = k, y = moranI), color = 'black') +
geom_point(aes(x = k, y = moranI), color = 'red') +
labs(x = 'k', y = 'I de Moran') +
theme_bw()
# Graphique pour les valeurs d'AIC
plot2 <- ggplot(df_plot) +
geom_line(aes(x = k, y = aic), color = 'black') +
geom_point(aes(x = k, y = aic), color = 'red') +
labs(x = 'k', y = 'AIC')+
theme_bw()
# Combinaison des deux graphiques
ggarrange(plot1, plot2)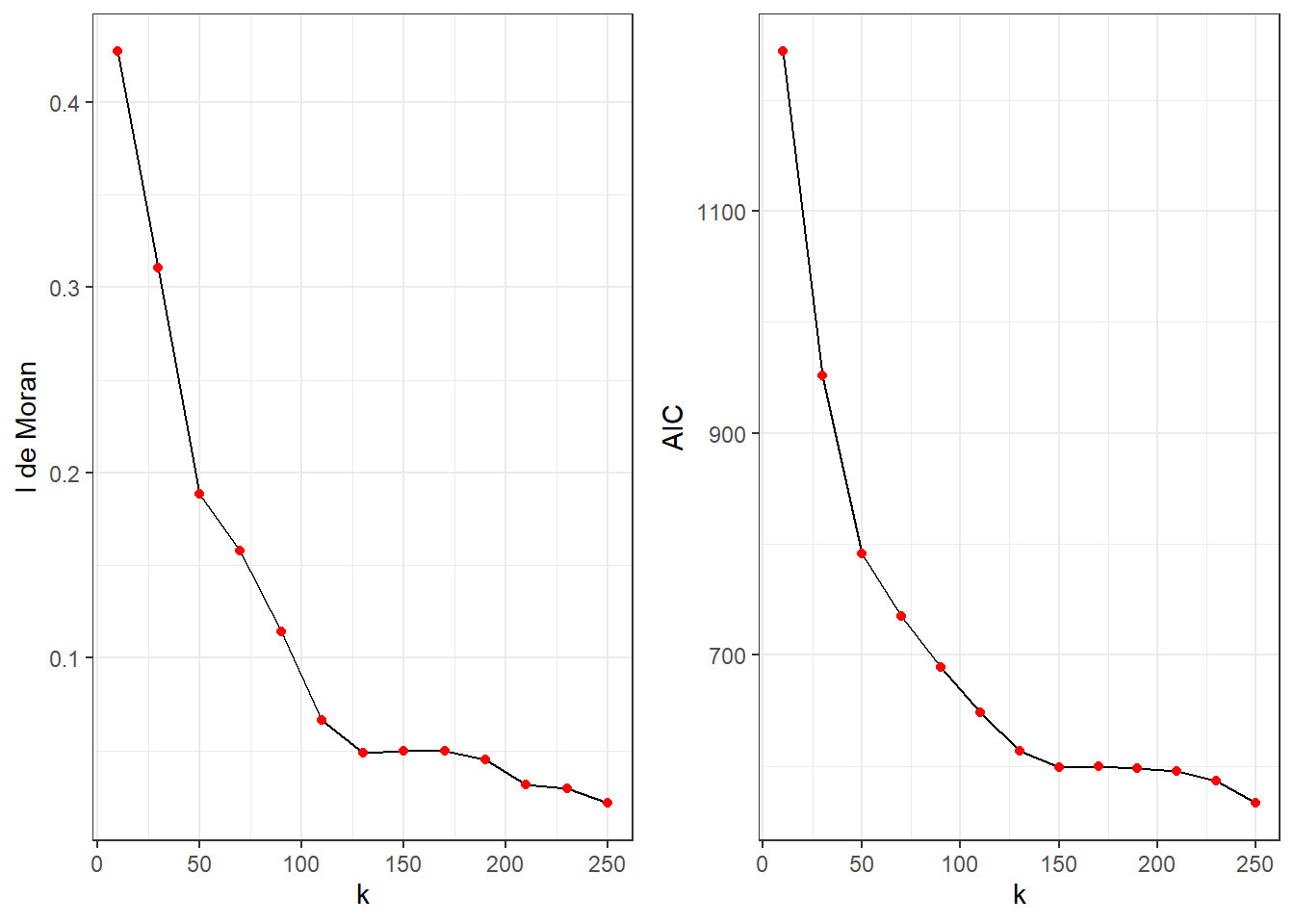
La figure 6.14 permet de constater que l’AIC et le I de Moran diminuent à mesure que \(k\) augmente. Pour le I de Moran, nous constatons qu’au-delà de \(k = 100\), nous passons à des valeurs inférieures à 0,05. Aussi l’AIC semble se stabiliser lorsque \(k = 150\). Nous pourrions donc ajuster un modèle avec \(k = 150\) pour avoir un bon compromis entre AIC et réduction du I de Moran des résidus.
gam2 <- gam(alr_val ~ prt_minorite_vis + prt_monoparental + revenu_median +
acs_idx_emp_tc_peak + acs_idx_emp_pieton +
s(ID_LOC, bs = 'mrf', xt = list(nb = nb), k = 150),
data = data_mtl, family = scat)
res <- simulateResiduals(gam2, plot = FALSE)
plot(res)
summary(gam2)
Family: Scaled t(3.245,0.22)
Link function: identity
Formula:
alr_val ~ prt_minorite_vis + prt_monoparental + revenu_median +
acs_idx_emp_tc_peak + acs_idx_emp_pieton + s(ID_LOC, bs = "mrf",
xt = list(nb = nb), k = 150)
Parametric coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -2.555219 0.108923 -23.459 < 2e-16 ***
prt_minorite_vis 1.303376 0.106976 12.184 < 2e-16 ***
prt_monoparental 0.907048 0.239301 3.790 0.000150 ***
revenu_median -0.008566 0.001473 -5.816 6.04e-09 ***
acs_idx_emp_tc_peak 3.118112 0.199688 15.615 < 2e-16 ***
acs_idx_emp_pieton -1.102568 0.288893 -3.817 0.000135 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Approximate significance of smooth terms:
edf Ref.df Chi.sq p-value
s(ID_LOC) 126.7 144.4 2219 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
R-sq.(adj) = 0.925 Deviance explained = 83.7%
-REML = 417.26 Scale est. = 1 n = 986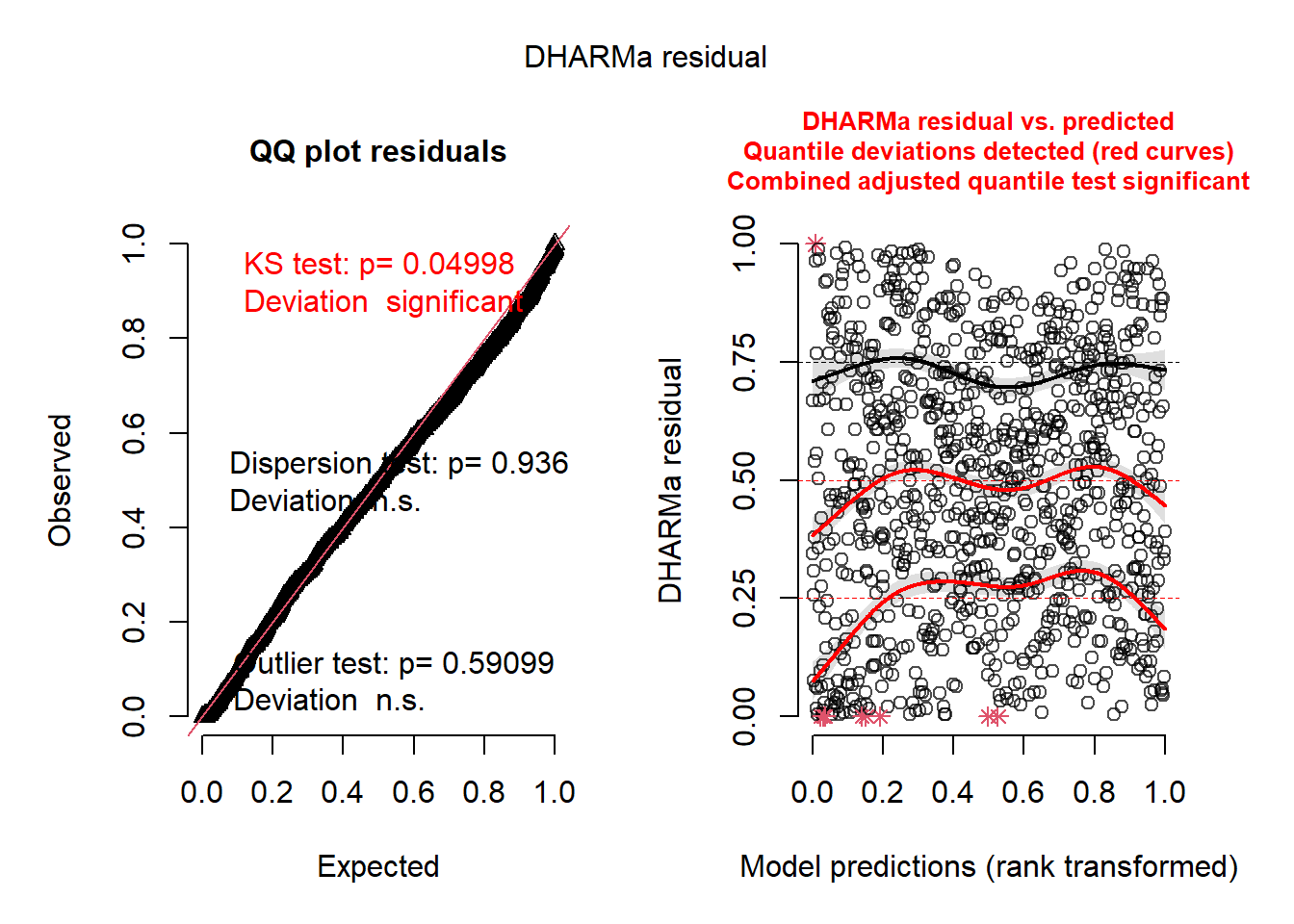
| Variable | Coefficient | exp(coefficent) | Valeur de p |
|---|---|---|---|
| Constante | -2,555 | 0,078 | 0 |
| prt_minorite_vis | 1,303 | 3,682 | 0 |
| prt_monoparental | 0,907 | 2,477 | 0 |
| revenu_median | -0,009 | 0,991 | 0 |
| acs_idx_emp_tc_peak | 3,118 | 22,604 | 0 |
| acs_idx_emp_pieton | -1,103 | 0,332 | 0 |
| R2 ajusté = 0,9255. |
Il apparaît que les résidus simulés de ce modèle suivent une distribution assez proche d’une distribution uniforme. Nous constatons aussi que toutes les variables indépendantes sont encore significatives et affectent notre variable dépendante dans la même direction (tableau 6.2).
moran.mc(residuals(res), listw = queen_w, nsim = 999, zero.policy = TRUE)
Monte-Carlo simulation of Moran I
data: residuals(res)
weights: queen_w
number of simulations + 1: 1000
statistic = -0.022059, observed rank = 145, p-value = 0.855
alternative hypothesis: greaterNous avons bien résolu le problème de l’autocorrélation spatiale de résidus. Nous pouvons donc à présent visualiser l’effet spatial de notre Markov random field. Pour cela, nous allons une fois encore appliquer la méthode des effets marginaux.
# On extrait toutes les observations du jeu de données
pred_df <- data_mtl[c('prt_minorite_vis', 'prt_monoparental', 'revenu_median',
'acs_idx_emp_tc_peak', 'acs_idx_emp_pieton', 'ID_LOC')]
# On met toutes les valeurs à 0 sauf l’identifiant des SR
pred_df[c(1:5)] <- 0
# On effectue la prédiction
pred_df$log_ratio <- predict.gam(gam2, newdata = pred_df, type = 'link')
# On retire l’effet de la constante
pred_df$log_ratio <- pred_df$log_ratio - gam2$coefficients[[1]]
# On bascule en exponentiel pour avoir l’effet sur le ratio
pred_df$effet_sp <- exp(pred_df$log_ratio)
results_mrf <- summary(gam2)
# on peut maintenant cartographier cet effet
# map_mrf <- tm_shape(pred_df) +
# tm_fill(col="effet_sp", n = 7,
# style = "jenks",
# midpoint = exp(0),
# legend.format = list(text.separator = "à",
# decimal.mark = ",",
# big.mark = " ",digits = 2),
# palette = "-RdBu", title = paste0('Effet du MRF\n(edf = ', round(results_mrf$edf), ')')) +
# tm_layout(frame=FALSE, legend.outside = TRUE) +
# tm_scale_bar(breaks = c(0,10))
map_mrf <- tm_shape(pred_df)+
tm_polygons(
col = NULL,
fill = "effet_sp",
fill.scale = tm_scale_intervals(
style = "jenks",
n = 7,
midpoint = exp(0),
values = "-brewer.rd_bu",
label.format = legende_parametres
),
fill.legend = tm_legend(
title = paste0('Effet du MRF\n(edf = ',
round(results_mrf$edf), ')'),
frame = FALSE,
position = tm_pos_out("right", pos.v = "center")
)
) +
tm_shape(data_mtl) +
tm_borders('darkgrey', lwd = 0.01) +
tm_layout(frame = FALSE)
tmap_arrange(map_spline, map_mrf, nrow = 2)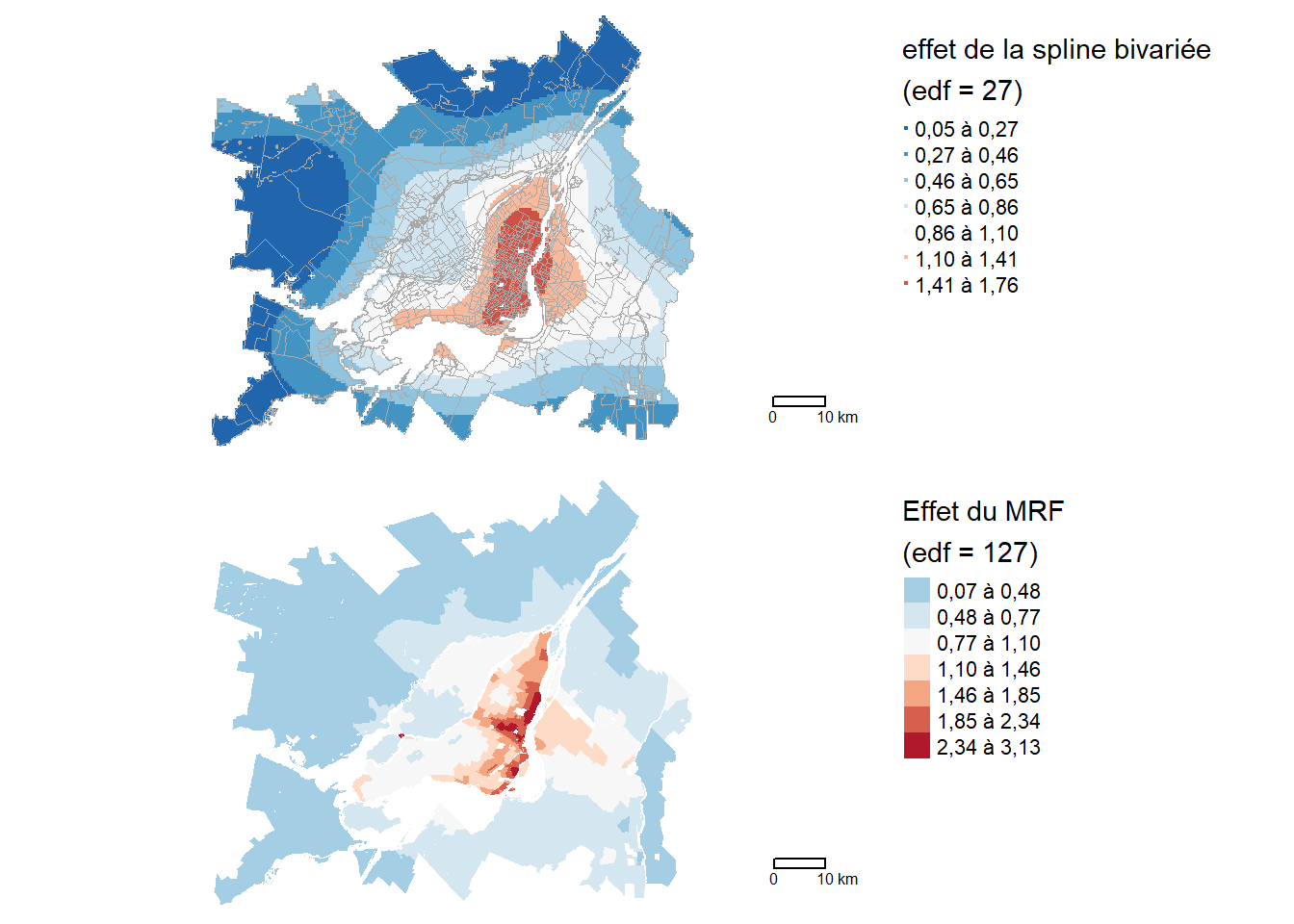
Ce terme spatial ressemble beaucoup à celui que nous avions obtenu avec la spline bivariée construite avec les coordonnées des centroïdes. Cependant, nous lui avons accordé un plus grand nombre de degrés de liberté et il s’ajuste mieux à la géographie de nos secteurs de recensement (polygones). Il aurait été possible de donner plus de flexibilité à la spline bivariée en utilisant également le paramètre k, elle serait cependant restée moins adaptée que le MRF. Par contre, l’avantage intéressant de l’approche par spline bivariée est qu’elle permet de prédire des valeurs à de nouvelles localisations, ce que ne permet pas le MRF.
6.6 Quiz de révision
Quelle est l’hypothèse clé des modèles de régression linéaire classique qui est assouplie dans les GAM?
Relisez au besoin la section 6.1.
Comment un modèle GAM peut-il être utilisé pour intégrer l’espace?
Relisez au besoin la section 6.3.
Dans quel cas préfère-t-on utiliser un RMF plutôt qu’une spline bivariée sur les coordonnées géographiques?
Relisez au besoin la section 6.4.
Pour analyser l’effet spatial modélisé avec une spline, on peut :
Relisez au besoin la section 6.5.2.
6.7 Exercices de révision
Exercice 1. Réalisation d’un modèle GAM aspatiale
library(sf)
library(mgcv)
library(car)
library(DHARMa)
library(mgcViz)
library(spdep)
library(dplyr)
# Chargement du jeu de données sur l’agglomération lyonnaise
load("data/Lyon.Rdata")
# Vérification de la multicolinéarité (VIF)
vif(lm(NO2 ~ Pct0_14+Pct_65+Pct_Img+Pct_brevet+NivVieMed, data = LyonIris))
# Construction du modèle GLM gaussien
Modele.GAM1 <- gam(à compléter)
# Résidus simulés du modèle gaussien
GAM1.res <- à compléter
plot(GAM1.res)
# Construction du modèle GLM avec une distribution de Student
Modele.GAM2 <- gam(à compléter)
# Résidus simulés avec une distribution de Student
GAM2.res <- à compléter
plot(GAM2.res)
# Comparaison des deux modèles
AIC(Modele.GAM1, Modele.GAM2)
# Résultats du modèle gaussien
summary(à compléter)
# Matrice de contiguïté selon le partage d’un nœud
queen_nb <- à compléter
queen_w <- à compléter
# I de Moran sur les résidus gaussiens
moran.mc(residuals(à compléter))
# I de Moran sur les résidus simulés
moran.mc(à compléter)Correction à la section 11.6.1.
Exercice 2. Réalisation d’un modèle GAM avec une spline bivariée
# Chargement du jeu de données sur l’agglomération lyonnaise
load("data/Lyon.Rdata")
# Ajout des coordonnées x et y dans la couche sf LyonIris
à compléter
# Modèle GAM avec la distribution de student et une spline
# sur les coordonnées x et y avec la distribution de Student
Modele.GAMSpline <- à compléter
summary(Modele.GAMSpline)Correction à la section 11.6.2.