| SLX | SAR | SEM | SDM | SDEM | |
|---|---|---|---|---|---|
| Externalités spatiales | X | X | X | ||
| Effets d’entraînement | X | X | |||
| Omission de variables | X | X | |||
| Hétérogénéité spatiale | X | X | |||
| Effets mixtes | X | X | |||
| Application de la matrice de pondération spatiale | VI | VD | TE | VI et VD | VI et TE |
| VD = Variable dépendante. VI = Variables indépendantes. TE = terme d’erreur. |
3 Modèles d’économétrie spatiale
Dans ce chapitre, nous décrivons uniquement les modèles économétriques spatiaux dont la variable dépendante est continue. Sommairement, ces modèles sont des extensions de la régression linéaire multiple, mais dans lequel une spécification explicite des relations spatiales entre les observations est introduite. Cette spécification vise ultimement à capter des effets spatiaux qui influencent le processus générateur de données (PGD), c’est-à-dire le modèle économétrique que nous spécifions.
Objectifs d’apprentissage visés dans ce chapitre
À la fin de ce chapitre, vous devriez être en mesure de :
- saisir les raisons motivant le choix d’un modèle de régression (externalités, effets d’entraînement, effets mixtes, etc.);
- comprendre les différents modèles spatiaux autorégressifs (SLX, SAR, SEM, SDM, SDEM, Manski);
- utiliser une stratégie pour choisir un modèle (tests du multiplicateur de Lagrange, tests du ratio de vraisemblance, critère d’information d’Akaike);
- vérifier si le modèle autorégressif a corrigé ou non la dépendance spatiale du modèle MCO;
- mettre en pratique ces modèles spatiaux dans R.
Liste des packages utilisés dans ce chapitre
- Pour importer et manipuler des fichiers géographiques :
sfpour importer et manipuler des données vectorielles.
- Pour construire des cartes et des graphiques :
tmapest certainement le meilleur package pour la cartographie.ggplot2etggpubrpour construire des graphiques.
- Pour construire des modèles spatiaux :
spdeppour construire des matrices de pondération spatiales et calculer le I de Moran.spatialregpour construire des modèles économétriques spatiaux.
Modèles d’économétrie spatiale pour une variable dépendante continue
Avant de lire ce chapitre, il convient de bien maîtriser la régression linéaire multiple. Une brève récapitulation est proposée à la section 1.5.
3.1 Les différents modèles spatiaux autorégressifs
Selon Jean Dubé et Diègo Legros, quelques raisons expliquent « le choix d’un modèle autorégressif : la présence d’externalités, les effets d’entraînement, l’omission de variables importantes, la présence d’hétérogénéité spatiale des comportements, les effets mixtes » (2014, 120). Les effets mixtes représentent une combinaison d’effets spatiaux. Dans tous les cas, la prise en compte des effets spatiaux passe par la spécification d’une matrice de pondération spatiale, notée \(W\) et de dimension (\(N \times N\)). Une synthèse des différents modèles spatiaux autorégressifs, décrits dans les sections suivantes, est présentée au tableau 3.1, indiquant s’ils sont ou non mixtes, et le type d’effet qu’ils permettent de prendre en compte.
3.1.1 Modèle SLX : prise en compte des caractéristiques des voisins
3.1.1.1 Description du modèle SLX
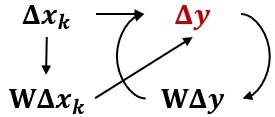
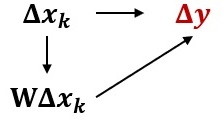
Dans un modèle SLX (spatial lag of X model), la dimension spatiale est intégrée par une possible influence des variables indépendantes des observations voisines ou des caractéristiques des voisins. Cette spécification vise habituellement à intégrer ce que l’on identifie dans la littérature par les effets d’externalités spatiales, c’est-à-dire capter l’influence des caractéristiques d’un voisin (\(\mathbf{W}\Delta x_k\)) sur le comportement d’intérêt d’une observation donnée (\(\Delta \mathbf{y}\)) (figure 3.1).
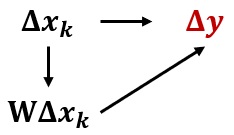
Deux principaux avantages sont liés à cette spécification. Premièrement, cette approche peut se faire simplement en ajoutant des variables à l’équation de départ, soit la spécification du PGD original. La création de variables indépendantes, supposées exogènes, spatialement décalées peut être effectuée de manière simple (section 1.3). Deuxièmement, ce modèle peut être estimé par la méthode des moindres carrés ordinaire (MCO), ce qui n’est pas possible avec les autres spécifications.
Rappel sur les variables spatialement décalées
Dans le premier chapitre (section 1.3), nous avons vu comment calculer une variable spatialement décalée avec une matrice de pondération spatiale (figure 1.13). À titre de rappel, lorsque cette dernière est standardisée en ligne, elle correspond à la valeur moyenne dans les unités voisines ou proches (dépendamment si la matrice est définie selon la contiguïté ou la proximité).
Le modèle SLX prend la spécification suivante :
\[ \mathbf{y}=\mathbf{\iota}\alpha+\mathbf{X\beta}+\mathbf{WX\theta}+\mathbf{\varepsilon} \tag{3.1}\]
Où :
\(\mathbf{y}\) est la variable dépendante, soit un vecteur de dimension \((N \times 1)\) où N est le nombre total d’observations mobilisées dans l’analyse, avec \(i=1,2,\dots,N\).
\(\iota\) est un vecteur de dimension \((N \times 1)\) comportant uniquement des valeurs de 1.
\(\mathbf{X}\) est une matrice de dimension \((N \times K)\) renfermant l’ensemble des \(K\) vecteurs de variables explicatives en plus d’une colonne de 1, dans la première colonne de la matrice, pour la constante, d’où \((K+1)\).
\(\alpha\) est un scalaire identifiant l’ordonnée à l’origine.
\(\beta\) est un vecteur de dimension \((K+1)\) qui renferme l’ensemble des coefficients de régression, pour les \(K\) variables indépendantes et la constante.
\(\mathbf{WX}\) est une matrice de variables indépendantes décalées spatialement, résultant d’une opération matricielle simple, soit \(\mathbf{WX} = \mathbf{W} \times \mathbf{X}\), où \(W\) est de dimension \((N×N)\), \(\mathbf{X}\) est de dimension \((N \times K)\), d’où \(\mathbf{WX}\) est de dimension \((N \times K)\), où chaque observation représente la moyenne des valeurs des variables indépendantes autour d’une observation donnée.
\(\theta\) est un vecteur de coefficients associés aux valeurs spatialement décalées des variables indépendantes (excluant la constante) de dimension \((K \times 1)\).
\(\varepsilon\) est un vecteur de dimension \((N \times 1)\) des termes d’erreurs.
Le PGD suggère que la valeur de chaque unité spatiale du modèle est ainsi expliquée à la fois par ses propres caractéristiques et celles de ses voisins ou des observations à proximité en fonction de la matrice de pondération spatiale (\(\mathbf{W}\)).
Une des particularités du modèle SLX est qu’il introduit une complexité dans l’interprétation des résultats et le calcul des effets marginaux puisque la variable \(x_k\) apparaît à deux endroits dans le modèle : d’abord dans la matrice des variables indépendantes originales (\(\mathbf{X}\)) et ensuite dans la matrice de variables indépendantes spatialement décalées (\(\mathbf{WX}\)). Lorsque la matrice de pondérations est standardisée en ligne, le calcul des effets marginaux est alors donné par la dérivée partielle suivante :
\[ \frac{\partial y}{\partial x_k} = \mathbf{I} \beta_k + \mathbf{W} \theta_k \tag{3.2}\]
Pour une matrice de pondération spatiale standardisée en ligne, cette expression se réduit à la valeur du coefficient associé à la variable indépendante originale, \(\beta_k\), en plus de la valeur du coefficient associé à la variable décalée spatialement, \(\theta_k\). L’expression synthétise l’effet marginal total, alors que le coefficient \(\beta_k\) est habituellement désigné par l’effet direct et le coefficient \(\theta_k\) synthétise l’effet indirect, puisque venant des voisins.
C’est d’ailleurs la valeur du coefficient \(\theta_k\) qui introduit ce que l’on qualifie d’externalité spatiale. Elle exprime comment la variable dépendante varie lorsque les caractéristiques des voisins changent. Les changements dans la variable d’intérêt peuvent ainsi venir d’une variation des caractéristiques des voisins.
Ce modèle est aussi désigné sous le terme d’effet spatial local, par opposition à l’effet global (voir modèle SAR, section 3.1.2). La variation des caractéristiques des voisins a une portée limitée sur le changement de valeur de la variable dépendante. Seulement certaines observations sont affectées : celles dont les caractéristiques des voisins ont changé.
Modèle SLX et correction de la dépendance spatiale du modèle MCO de départ
Si le modèle SLX offre une solution intéressante pour régler le potentiel problème d’autocorrélation spatiale des résidus, rien n’assure pour autant qu’il permet de régler tous les problèmes, même si les coefficients associés aux variables spatialement décalées sont statistiquement significatifs. L’inclusion de variables indépendantes additionnelles peut ne pas suffire à capter ce qui, au départ dans la régression par MCO, se cache dans les résidus du modèle. Un test d’autocorrélation spatiale sur les résidus du modèle SLX est un réflexe nécessaire à avoir.
3.1.1.2 Modèle SLX dans R
Pour illustrer la mise en œuvre dans R des différents modèles d’économétrie spatiale, nous utilisons le jeu de données sur Lyon (section 1.1.1). Les modèles seront construits avec le dioxyde d’azote (NO2) comme variable dépendante et cinq variables sociodémographiques comme variables indépendantes (section 1.1.1). Le modèle MCO (non spatial) a déjà été présenté à la section 1.6.1.
Le modèle SLX est construit avec la fonction lmSLX du package spatialreg (Bivand, Millo et Piras 2021). Dans le code ci-dessous, remarquez le paramètre listw = w_rook qui est utilisé pour spécifier la matrice de pondération spatiale.
## Chargement des packages et des données
library(sf)
library(tmap)
library(spdep)
library(spatialreg)
load("data/Lyon.Rdata")
## Matrice de contiguïté selon le partage d’un segment (Rook)
nb_rook <- poly2nb(LyonIris, queen = FALSE)
w_rook <- nb2listw(nb_rook, zero.policy = TRUE, style = "W")
## Construction du modèle MCO
modele_MCO <- lm(NO2 ~ Pct0_14 + Pct_65 + Pct_Img + Pct_brevet + NivVieMed,
data = LyonIris)
## Construction du modèle SLX
modele_SLX <- spatialreg::lmSLX(NO2 ~ Pct0_14 + Pct_65 + Pct_Img + Pct_brevet + NivVieMed,
listw = w_rook, # matrice de pondération spatiale
data = LyonIris) # dataframe
## Résultats du modèle
summary(modele_SLX)
Call:
lm(formula = formula(paste("y ~ ", paste(colnames(x)[-1], collapse = "+"))),
data = as.data.frame(x), weights = weights)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5.068e+01 4.188e+00 1.210e+01 1.040e-29
Pct0_14 -2.040e-01 6.268e-02 -3.255e+00 1.211e-03
Pct_65 -3.771e-02 5.361e-02 -7.033e-01 4.822e-01
Pct_Img 1.041e-01 4.849e-02 2.146e+00 3.235e-02
Pct_brevet -7.363e-02 3.550e-02 -2.074e+00 3.857e-02
NivVieMed -1.844e-01 1.106e-01 -1.667e+00 9.617e-02
lag.Pct0_14 -7.759e-01 1.030e-01 -7.537e+00 2.315e-13
lag.Pct_65 -6.454e-02 9.115e-02 -7.081e-01 4.792e-01
lag.Pct_Img 6.465e-01 8.593e-02 7.524e+00 2.526e-13
lag.Pct_brevet -3.013e-01 6.157e-02 -4.893e+00 1.344e-06
lag.NivVieMed -1.805e-02 1.750e-01 -1.031e-01 9.179e-01Effets directs, indirects et totaux
La formulation d’un modèle SLX implique deux types d’effets pour les variables indépendantes (\(X\)) :
Les effets directs, soit ceux des caractéristiques des entités spatiales. Ils correspondent aux coefficients \(\beta\) des variables indépendantes (\(\mathbf{X}\)). Autrement dit, pour une observation \(i\), à chaque augmentation d’une unité d’une caractéristique \(\mathbf{X}\), la valeur de \(y_i\) va varier (augmenter ou diminuer) en fonction du coefficient \(\beta\).
Les effets indirects, soit ceux des caractéristiques des entités spatiales voisines ou proches définies selon la matrice de pondération spatiale. Ils correspondent aux coefficients \(\theta\) des variables indépendantes spatialement décalées (\(\mathbf{WX}\)). Autrement dit, les valeurs de \(\mathbf{WX}\) des entités spatiales proches ou voisines \(j\) de \(i\) vont aussi être amenées à varier, impactant alors les valeurs \(y_i\) selon les coefficients \(\theta\).
Pour calculer l’impact total, il suffit de sommer son effet direct (\(\beta_k\)) et son effet indirect (\(\theta_k\)) pour obtenir son effet total.
Le code suivant permet de calculer ces effets directs et indirects.
## Effets directs, indirects et totaux (uniquement les coefficients)
impacts(modele_SLX)Impact measures (SlX, glht):
Direct Indirect Total
Pct0_14 -0.20403803 -0.77590830 -0.9799463
Pct_65 -0.03770918 -0.06453809 -0.1022473
Pct_Img 0.10406359 0.64653923 0.7506028
Pct_brevet -0.07363272 -0.30128171 -0.3749144
NivVieMed -0.18440960 -0.01804718 -0.2024568## Effets directs, indirects et totaux (coefficients, valeurs de z et de p)
summary(impacts(modele_SLX))Impact measures (SlX, glht, n-k):
Direct Indirect Total
Pct0_14 -0.20403803 -0.77590830 -0.9799463
Pct_65 -0.03770918 -0.06453809 -0.1022473
Pct_Img 0.10406359 0.64653923 0.7506028
Pct_brevet -0.07363272 -0.30128171 -0.3749144
NivVieMed -0.18440960 -0.01804718 -0.2024568
========================================================
Standard errors:
Direct Indirect Total
Pct0_14 0.06268202 0.10295210 0.10045332
Pct_65 0.05361420 0.09114695 0.08556272
Pct_Img 0.04849085 0.08593145 0.08060028
Pct_brevet 0.03549819 0.06157121 0.05975821
NivVieMed 0.11063207 0.17499339 0.14911021
========================================================
Z-values:
Direct Indirect Total
Pct0_14 -3.2551283 -7.5365951 -9.755241
Pct_65 -0.7033432 -0.7080664 -1.194998
Pct_Img 2.1460460 7.5238953 9.312658
Pct_brevet -2.0742665 -4.8932234 -6.273857
NivVieMed -1.6668729 -0.1031306 -1.357766
p-values:
Direct Indirect Total
Pct0_14 0.0011334 4.8184e-14 < 2.22e-16
Pct_65 0.4818419 0.47890 0.23209
Pct_Img 0.0318693 5.3069e-14 < 2.22e-16
Pct_brevet 0.0380546 9.9198e-07 3.5221e-10
NivVieMed 0.0955397 0.91786 0.17454 À la lecture des valeurs de p, nous constatons que seule la variable Pct0_14 a des impacts direct et indirect significatifs au seuil 0,01. L’augmentation d’un point de pourcentage de la population de moins de 15 ans est associée localement à une réduction de 0,20 de la concentration annuelle du dioxyde d’azote. La même augmentation d’un point de pourcentage dans les entités voisines entraîne une réduction de 0,78. L’effet total est donc une réduction de 0,98.
Dépendance spatiale du modèle SLX?
Ce modèle a-t-il corrigé le problème de dépendance spatiale du modèle de régression linéaire classique? Avec une valeur du I de Moran de 0,605 (p < 0,001), les résidus sont toujours fortement autocorrélés spatialement (figure 3.2).
legende_parametres <- list(text.separator = "à",
decimal.mark = ",",
big.mark = " ")
lm.morantest(modele_SLX, w_rook, alternative="two.sided")
Global Moran I for regression residuals
data:
model: lm(formula = formula(paste("y ~ ", paste(colnames(x)[-1],
collapse = "+"))), data = as.data.frame(x), weights = weights)
weights: w_rook
Moran I statistic standard deviate = 21.951, p-value < 2.2e-16
alternative hypothesis: two.sided
sample estimates:
Observed Moran I Expectation Variance
0.6046602748 -0.0072844321 0.0007771643 LyonIris$SLX.Residus <- residuals(modele_SLX)
tmap_mode("plot")
tm_shape(LyonIris)+
tm_polygons(
col = NULL,
lwd=.2,
fill = "SLX.Residus",
fill.scale = tm_scale_intervals(
n = 5,
midpoint = 0,
style = "quantile",
values = "-brewer.rd_bu",
label.format = legende_parametres
),
fill.legend = tm_legend(
title = "Résidus",
frame = FALSE,
position = tm_pos_out("right", pos.v = "center")
)
) +
tm_layout(frame = FALSE) +
tm_scale_bar(breaks = c(0,5))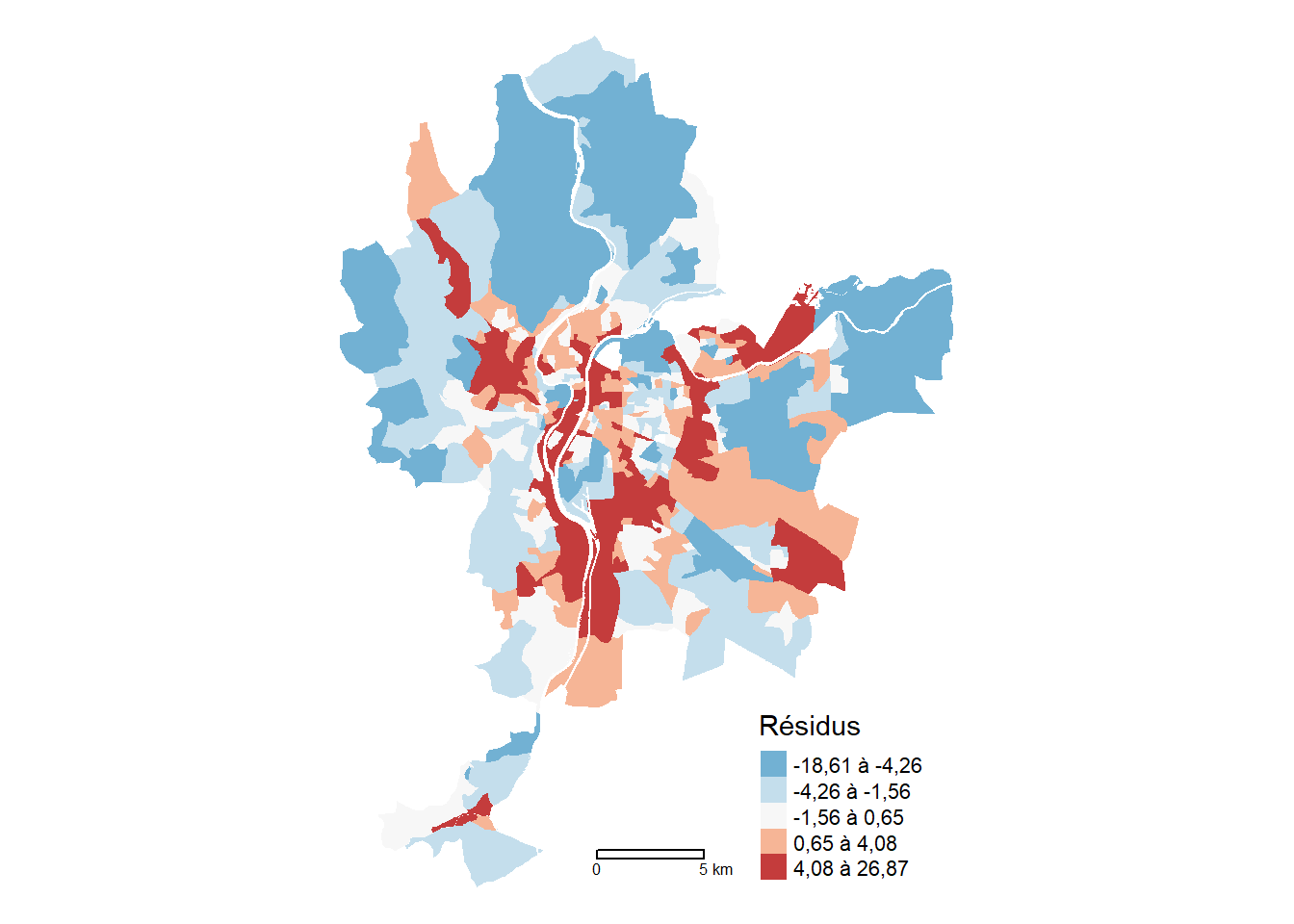
3.1.2 Modèle SAR : autocorrélation spatiale sur la variable dépendante
3.1.2.1 Description du Modèle SAR
Une autre spécification consiste à inclure, comme variable additionnelle au modèle de départ, la variable dépendante spatialement décalée, notée \(\mathbf{Wy}\). Le modèle, généralement désigné par le terme SAR (spatial autoregressive), prend la forme suivante :
\[ \mathbf{y} = \rho \mathbf{Wy} + \iota \alpha + \mathbf{X} \beta + \epsilon \tag{3.3}\]
Où :
\(\mathbf{Wy}\) est un vecteur de la variable dépendante spatialement décalée de dimension \((N \times 1)\).
\(\rho\) est un paramètre (scalaire, donc de dimension (\(1 \times 1\))) autorégressif, qui varie habituellement entre -1 et 1 (autrement un problème de non-stationnarité survient).
Par opposition au modèle SLX, cet ajout nécessite une autre méthode d’estimation que les moindres carrés ordinaire puisque la variable additionnelle du côté droit de l’équation est endogène et qu’elle dépend des valeurs de la variable dépendante, qui elles, dépendent des valeurs prises par les caractéristiques des observations. La simple construction de variables spatialement décalées ne peut être considérée. Le processus générateur des données (PGD) s’exprime donc sous une forme un peu plus complexe, soit :
\[ y = (\mathbf{I} - \rho W)^{-1} \left[ \iota \alpha + X \beta + \varepsilon \right] \tag{3.4}\]
Où :
- \(\mathbf{I}\) est une matrice identité, c’est-à-dire une matrice où la diagonale comporte des 1 et où les autres éléments sont nuls, de dimension \((N \times N)\).
Le modèle nécessite une méthode d’estimation appropriée. La première approche, par maximum de vraisemblance, fut proposée dès le départ par Luc Anselin (1988). Cette approche a été largement mobilisée dans les premières applications. Bien qu’intéressante, cette approche repose sur certaines hypothèses, dont la distribution du terme d’erreur et l’absence d’hétéroscédasticité.
Plus récemment, Kelejian et Prucha (1998) ont proposé une approche basée sur les moindres carrés généralisés (MCG). Cette approche a l’avantage d’être plus rapide en plus de permettre de corriger l’absence d’hétéroscédasticité. Elle a cependant le désavantage de reposer sur l’hypothèse importante d’exogénéité de la matrice de pondération spatiale, qui sert d’instrument lors du processus d’estimation.
Ce modèle est habituellement qualifié d’effet de débordement ou d’effet d’entraînement. Comparativement au modèle SLX, les effets marginaux sont identifiés comme étant globaux puisqu’une variation de la valeur de la variable dépendante introduit une variation dans la valeur des variables dépendantes décalées spatialement qui, à leur tour, influencent la variation dans les valeurs dépendantes des observations voisines et ainsi de suite (figure 3.3). Cette boucle de rétroaction peut être interprétée comme la résultante d’un équilibre général spatial.
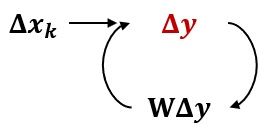
La dérivée partielle du modèle SAR procure une forme plus complexe :
\[ \frac{\partial \mathbf{y}}{\partial x_k}=\left(\mathbf{I}-\rho\mathbf{W}\right)^{-1}\beta_k \tag{3.5}\]
C’est donc dire que les effets marginaux sont un peu plus complexes à analyser et à calculer. Une approche classique, celle proposée par LeSage et Pace (2009), consiste à calculer le résultat du produit matriciel à partir d’une approximation basée sur une somme à perpétuité et à extraire la diagonale de la matrice résultante. La diagonale représente l’effet direct et la somme des éléments hors diagonale représentent les effets indirects, afin d’obtenir l’effet marginal total. C’est habituellement cette décomposition qui est proposée par la plupart des logiciels, incluant R. Cette approche peut paraître un peu plus complexe et plus difficilement interprétable puisque les effets marginaux directs ne sont pas définis par les coefficients \(\beta_k\).
Deux autres approches sont également proposées. Une première, proposée par Abreu et al. (2004), reprend la sommation matricielle, mais en proposant une décomposition différente sur la base d’un vocabulaire différent également. Les auteurs proposent néanmoins que le coefficient de régression \(\beta_k\) s’interprète comme un effet direct.
Une seconde, proposée par Kim et al. (2003), Steimetz (2010), Dubé et Legros (2014) et Dubé et al. (2017), consiste essentiellement à tirer profit des propriétés de la matrice de pondération spatiale standardisée en ligne afin d’y proposer une décomposition simple. Dans ce cas, les auteurs proposent les règles suivantes pour calculer les effets marginaux :
\(\beta_k\) représente l’effet marginal direct.
\(\beta_k\left(1-\rho\right)^{-1}\), ou encore \(\frac{\beta_k}{\left(1-\rho\right)}\), identifie l’effet marginal total.
\({\rho\beta}_k\left(1-\rho\right)^{-1}\), ou encore \(\frac{\rho\beta_k}{\left(1-\rho\right)}\), représente l’effet marginal indirect qui peut être obtenu en retranchant l’effet direct de l’effet total.
Des tests non linéaires peuvent être mobilisés afin de tester la significativité des effets marginaux indirects et totaux, alors que le test de significativité du paramètre procure une façon simple de vérifier si l’effet direct est statistiquement significatif.
Tout comme pour la spécification SLX, rien n’indique pour autant que le modèle SAR permet de capter l’essentiel de l’autocorrélation spatiale résiduelle. Un test sur les résidus doit idéalement être mobilisé pour vérifier cette hypothèse critique. La détection d’une autocorrélation spatiale résiduelle significative peut invalider les résultats obtenus par cette approche.
3.1.2.2 Modèle SAR dans R
Le modèle SAR est construit avec la fonction lagsarlm du package spatialreg.
## Construction du modèle
modele_SAR <- lagsarlm(NO2 ~ Pct0_14 + Pct_65 + Pct_Img + Pct_brevet + NivVieMed,
listw = w_rook, # matrice de pondération spatiale
data = LyonIris, # dataframe
type = 'lag') # Modèle lag par défaut
## Résultats du modèle
summary(modele_SAR, Nagelkerke = TRUE)
Call:lagsarlm(formula = NO2 ~ Pct0_14 + Pct_65 + Pct_Img + Pct_brevet +
NivVieMed, data = LyonIris, listw = w_rook, type = "lag")
Residuals:
Min 1Q Median 3Q Max
-12.86859 -1.88111 -0.49760 0.94464 18.21351
Type: lag
Coefficients: (asymptotic standard errors)
Estimate Std. Error z value Pr(>|z|)
(Intercept) 7.838906 1.646232 4.7617 1.919e-06
Pct0_14 -0.098708 0.030554 -3.2306 0.001235
Pct_65 -0.034543 0.026957 -1.2814 0.200044
Pct_Img 0.030241 0.024491 1.2348 0.216917
Pct_brevet -0.019234 0.017855 -1.0772 0.281384
NivVieMed -0.098413 0.048985 -2.0090 0.044534
Rho: 0.87939, LR test value: 620.31, p-value: < 2.22e-16
Asymptotic standard error: 0.01942
z-value: 45.283, p-value: < 2.22e-16
Wald statistic: 2050.5, p-value: < 2.22e-16
Log likelihood: -1366.157 for lag model
ML residual variance (sigma squared): 10.181, (sigma: 3.1908)
Nagelkerke pseudo-R-squared: 0.78962
Number of observations: 506
Number of parameters estimated: 8
AIC: 2748.3, (AIC for lm: 3366.6)
LM test for residual autocorrelation
test value: 0.6198, p-value: 0.43112Dans les résultats ci-dessus, la valeur de rho est de 0,88 (LR = 620, p < 0,001), traduisant un très fort effet d’entraînement. Autrement dit, lorsqu’en moyenne la concentration de dioxyde d’azote augmente dans les IRIS voisines (\(\mathbf{Wy}\)), elle augmente aussi fortement dans chaque IRIS (\(\mathbf{y}\)).
Effets directs, indirects et totaux
À nouveau, il est possible d’utiliser la fonction impacts pour obtenir les effets marginaux directs et indirects.
## Effets directs, indirects et totaux (uniquement les coefficients)
impacts(modele_SAR, listw = w_rook, R = 999)Impact measures (lag, exact):
Direct Indirect Total
Pct0_14 -0.13878038 -0.6796248 -0.8184052
Pct_65 -0.04856624 -0.2378349 -0.2864012
Pct_Img 0.04251743 0.2082131 0.2507306
Pct_brevet -0.02704205 -0.1324283 -0.1594703
NivVieMed -0.13836534 -0.6775923 -0.8159576## Effets directs, indirects et totaux (coefficients, valeurs de z et de p)
summary(impacts(modele_SAR, listw = w_rook, R = 999), zstats = TRUE, short = TRUE)Impact measures (lag, exact):
Direct Indirect Total
Pct0_14 -0.13878038 -0.6796248 -0.8184052
Pct_65 -0.04856624 -0.2378349 -0.2864012
Pct_Img 0.04251743 0.2082131 0.2507306
Pct_brevet -0.02704205 -0.1324283 -0.1594703
NivVieMed -0.13836534 -0.6775923 -0.8159576
========================================================
Simulation results ( variance matrix):
========================================================
Simulated standard errors
Direct Indirect Total
Pct0_14 0.04210485 0.2350622 0.2727740
Pct_65 0.03751551 0.1939237 0.2305345
Pct_Img 0.03300792 0.1740032 0.2061379
Pct_brevet 0.02518608 0.1310968 0.1556966
NivVieMed 0.06724816 0.3526101 0.4164624
Simulated z-values:
Direct Indirect Total
Pct0_14 -3.324097 -2.964775 -3.067987
Pct_65 -1.206664 -1.157437 -1.169990
Pct_Img 1.291133 1.220895 1.237314
Pct_brevet -1.165542 -1.114266 -1.126757
NivVieMed -2.130460 -2.016131 -2.051032
Simulated p-values:
Direct Indirect Total
Pct0_14 0.00088705 0.003029 0.0021551
Pct_65 0.22756152 0.247094 0.2420050
Pct_Img 0.19665764 0.222126 0.2159704
Pct_brevet 0.24379952 0.265165 0.2598453
NivVieMed 0.03313362 0.043786 0.0402638L’interprétation des effets directs se rapproche de celle des coefficients classiques. Ainsi, selon ce modèle, l’augmentation du niveau de vie médian de 1000 € dans un IRIS est associée à une diminution moyenne de la concentration de dioxyde d’azote de 0,14 dans cet IRIS. L’effet total est de -0,82, indiquant qu’en moyenne, l’augmentation de 1000 € du niveau de vie médian dans un IRIS est associée à une diminution moyenne de 0,82 de la concentration de dioxyde d’azote dans l’ensemble des IRIS. Au final, l’effet indirect est simplement la différence entre l’effet total et l’effet direct. Nous pouvons constater ici que les effets indirects sont plus importants que les effets directs.
Dépendance spatiale du modèle SAR?
Ce modèle a-t-il corrigé le problème de dépendance spatiale du modèle de régression linéaire classique? Avec une valeur du I de Moran de -0,014 (p > 0,10), les résidus ne sont plus spatialement autocorrélés (figure 3.4).
## Résidus du modèles
LyonIris$SAR.Residus <- resid(modele_SAR)
## Autocorrélation spatiale des résidus
moran.mc(LyonIris$SAR.Residus, w_rook, nsim = 999)
Monte-Carlo simulation of Moran I
data: LyonIris$SAR.Residus
weights: w_rook
number of simulations + 1: 1000
statistic = -0.014281, observed rank = 335, p-value = 0.665
alternative hypothesis: greater## Cartographie des résidus
legende_parametres <- list(text.separator = "à",
decimal.mark = ",",
big.mark = " ")
tm_shape(LyonIris)+
tm_polygons(
col = NULL,
lwd=.2,
fill = "SAR.Residus",
fill.scale = tm_scale_intervals(
n = 5,
midpoint = 0,
style = "quantile",
values = "-brewer.rd_bu",
label.format = legende_parametres
),
fill.legend = tm_legend(
title = "Résidus",
frame = FALSE,
position = tm_pos_out("right", pos.v = "center")
)
) +
tm_layout(frame = FALSE) +
tm_scale_bar(breaks = c(0,5))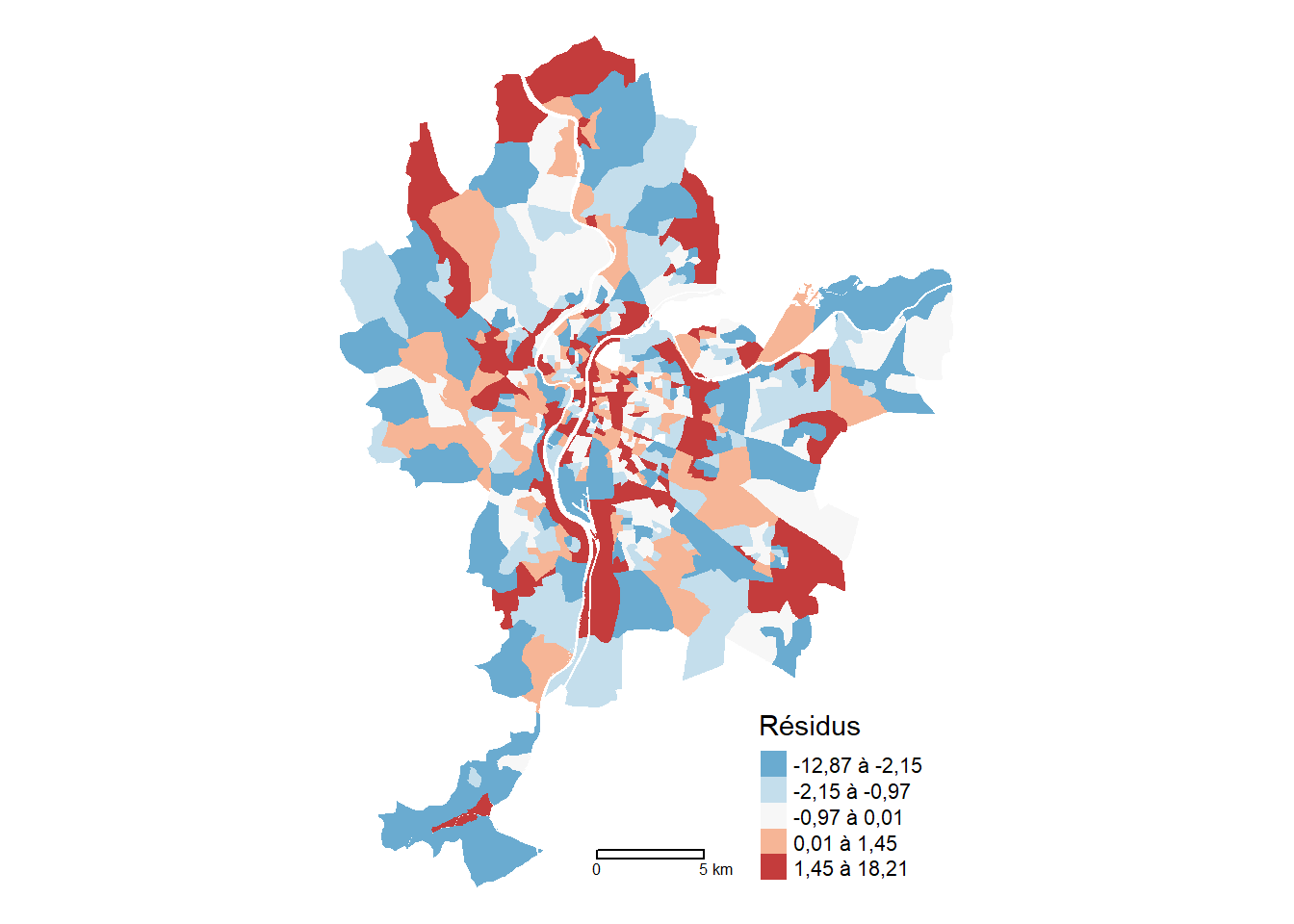
3.1.3 Modèle SEM : autocorrélation spatiale sur le terme d’erreur
3.1.3.1 Description du modèle SEM
L’autocorrélation spatiale résiduelle peut être liée à deux explications simples. La première est liée à l’omission de variables spatiales importantes et significatives, pour laquelle nous ne disposons d’aucune information spécifique. La seconde peut provenir d’une forme d’hétérogénéité spatiale qui n’est pas intégrée à l’analyse. Nous pouvons ainsi imaginer que les comportements sont liés dans l’espace pour des raisons qui ne sont pas observables, et encore moins mesurables.
Dans les deux cas, nous pouvons simplement corriger le problème sans pour autant tenter de tirer profit d’une forme spécifique de relations spatiales (externalités, effets d’entraînement). C’est essentiellement dans ces cas que les modèles avec une spécification autorégressive sur les termes d’erreurs (ou SEM – spatial error model) peuvent être intéressants : ils ne permettent pas d’apporter une richesse supplémentaire à l’analyse et à l’interprétation, mais ils permettent vraisemblablement de corriger le problème d’interdépendance des termes d’erreurs. Plus spécifiquement, le modèle SEM s’exprime par la spécification suivante :
\[ \mathbf{y}=\mathbf{\iota}\alpha+\mathbf{X\beta}+\mathbf{\nu} \tag{3.6}\]
\[ \mathbf{\nu}=\lambda\mathbf{W\nu}+\mathbf{\varepsilon} \]
Où :
\(\mathbf{W}\) est une matrice de pondération spatiale, standardisée en ligne, de dimension \(\left(N\times N\right)\).
\(\lambda\) est un paramètre (scalaire, donc de dimension \(\left(1\times1\right)\)) autorégressif qui varie habituellement entre -1 et 1 (autrement un problème de non-stationnarité survient).
\(\mathbf{\nu}\) est un vecteur de termes d’erreurs spatialement autocorrélés de dimension \(\left(N\times1\right)\).
\(\mathbf{\varepsilon}\) est un vecteur de termes supposés indépendants de dimension \(\left(N\times1\right)\).
La forme réduite du PGD est donné par l’expression suivante :
\[ \mathbf{y}=\mathbf{\iota}\alpha+\mathbf{X\beta}+\left(\mathbf{I}-\lambda\mathbf{W}\right)^{-1}\mathbf{\varepsilon} \tag{3.7}\]
Où :
- \(\mathbf{I}\) est une matrice identité, c’est-à-dire une matrice où la diagonale comporte des 1 et où les autres éléments sont nuls, de dimension \(\left(N\times N\right)\).
Tout comme pour le cas du modèle SAR, le modèle SEM ne peut être estimé par la méthode des moindres carrés ordinaire vu la forme complexe que prend le terme d’erreur dans la forme réduite du PGD. Le modèle est habituellement estimé par maximum de vraisemblance.
Un des avantages avec le modèle SEM est que l’interprétation des résultats est similaire à celle que l’on retrouve dans les régressions linéaires classiques. La dérivée partielle de la forme réduite du PGD est simplement égale au coefficient lié à la variable souhaitée :
\[ \frac{\partial\mathbf{y}}{\partial\mathbf{x}_k}=\mathbf{I}\beta_k \tag{3.8}\]
Or, l’avantage de la structure spatiale des données est justement d’apporter une richesse supplémentaire à l’analyse que l’on ne peut intégrer avec des données aspatiales. Pour cette raison, les modèles SEM ne sont pas particulièrement prisés par les chercheuses et chercheurs qui tentent d’intégrer l’espace aux modèles. Ils représentent une forme de solution de dernier recours lorsqu’il est impossible de capter la structure résiduelle spatiale autrement.
Tout comme pour les autres spécifications, il est judicieux de vérifier si le modèle permet adéquatement de contrôler l’autocorrélation résiduelle. À noter que le modèle SEM peut également mener à une réécriture qui, elle, permet d’intégrer des effets spatiaux qui permettent d’influencer l’interprétation des résultats. Cette forme est désignée par la spécification du modèle Durbin spatial.
3.1.3.2 Modèle SEM dans R
Le modèle SEM est construit avec la fonction errorsarlm du package spatialreg.
## Construction du modèle
modele_SEM <- errorsarlm(NO2 ~ Pct0_14 + Pct_65 + Pct_Img + Pct_brevet + NivVieMed,
listw = w_rook, # matrice de pondération spatiale
data = LyonIris) # dataframe
## Résultats du modèle
summary(modele_SEM, Nagelkerke = TRUE)
Call:errorsarlm(formula = NO2 ~ Pct0_14 + Pct_65 + Pct_Img + Pct_brevet +
NivVieMed, data = LyonIris, listw = w_rook)
Residuals:
Min 1Q Median 3Q Max
-12.86150 -1.83161 -0.44106 0.91029 17.94924
Type: error
Coefficients: (asymptotic standard errors)
Estimate Std. Error z value Pr(>|z|)
(Intercept) 30.544576 2.358173 12.9526 < 2e-16
Pct0_14 -0.035019 0.033393 -1.0487 0.29431
Pct_65 -0.026039 0.028970 -0.8988 0.36874
Pct_Img -0.016770 0.026176 -0.6407 0.52175
Pct_brevet 0.023708 0.019074 1.2430 0.21388
NivVieMed -0.146309 0.060273 -2.4274 0.01521
Lambda: 0.91138, LR test value: 613.15, p-value: < 2.22e-16
Asymptotic standard error: 0.01651
z-value: 55.201, p-value: < 2.22e-16
Wald statistic: 3047.2, p-value: < 2.22e-16
Log likelihood: -1369.737 for error model
ML residual variance (sigma squared): 9.9971, (sigma: 3.1618)
Nagelkerke pseudo-R-squared: 0.78662
Number of observations: 506
Number of parameters estimated: 8
AIC: 2755.5, (AIC for lm: 3366.6)Dans les résultats ci-dessus, la valeur de lambda est de 0,91 (LR = 613, p < 0,001), traduisant une très forte autocorrélation spatiale sur le terme d’erreur.
Dépendance spatiale du modèle SEM?
Ce modèle a-t-il corrigé le problème de dépendance spatiale du modèle de régression linéaire classique? Avec une valeur du I de Moran de -0,012 (p = 0,616), les résidus ne sont plus spatialement autocorrélés.
## Autocorrélation spatiale des résidus
moran.mc(resid(modele_SEM), w_rook, nsim = 999)
Monte-Carlo simulation of Moran I
data: resid(modele_SEM)
weights: w_rook
number of simulations + 1: 1000
statistic = -0.011827, observed rank = 357, p-value = 0.643
alternative hypothesis: greaterLes modèles MCO et SEM sont-ils différents?
Pour le vérifier, Pace et Lesage (2008) proposent d’appliquer le test de Hausman qui s’interprète comme suit :
Si p < 0,05, alors les coefficient du modèle MCO sont biaisés par l’erreur spatiale et il est préférable d’utiliser le modèle SEM. Cela est le cas pour notre modèle.
Si p > 0,05, les résultats des modèles ne sont pas différents et nous pouvons conserver le modèle MCO.
Hausman.test(modele_SEM)
Spatial Hausman test (asymptotic)
data: NULL
Hausman test = -467.64, df = 6, p-value < 2.2e-163.1.4 Modèle SDM : autocorrélation spatiale sur la variable dépendante et les variables indépendantes
3.1.4.1 Description du modèle SDM
Le modèle spatial Durbin (SDM - Spatial Durbin Model) est un modèle mixte qui permet à la fois d’intégrer la relation spatiale sur la variable dépendante (effets d’entraînement ou de débordement) et sur les variables indépendantes (externalités). Elle permet, explicitement, de combiner les modèles SLX et SAR bien que son inspiration soit issue d’une réécriture de la forme réduite du modèle SEM, où chaque élément est multiplié par le terme \(\mathbf{I}-\lambda\mathbf{W}\) :
\[ \mathbf{y}=\lambda\mathbf{Wy}+\mathbf{\iota}\alpha+\mathbf{X\beta}+\mathbf{WX\beta}\lambda+\mathbf{\varepsilon} \tag{3.9}\]
Où :
- \(\mathbf{\beta}\lambda\) est un nouvel ensemble de paramètres liés aux variables indépendantes spatialement décalées, qui est habituellement substitué par \(\mathbf{\theta}\).
Tout comme pour le SEM et le SAR, le modèle SDM ne peut être estimé par la méthode des moindres carrés ordinaire. Il faut recourir à la méthode du maximum de vraisemblance ou encore à la méthode des moments généralisés, cette dernière approche offrant une flexibilité plus intéressante pour la présence d’hétéroscédasticité.
De la même manière, les coefficients estimés par le modèle permettent une décomposition plus sophistiquée des effets marginaux. La forme réduite du PGD est donnée par :
\[ \mathbf{y}=\left(\mathbf{I}-\lambda\mathbf{W}\right)^{-1}\left[\mathbf{\iota}\alpha+\mathbf{X\beta}+\mathbf{WX\theta}+\mathbf{\varepsilon}\right] \tag{3.10}\]
Ainsi, le calcul des effets marginaux est donné par :
\[ \frac{\partial\mathbf{y}}{\partial\mathbf{x}_k}=\left(\mathbf{I}-\lambda\mathbf{W}\right)^{-1}\left[{\mathbf{I}\beta}_k+\mathbf{W}\theta_k\right] \tag{3.11}\]
En ce qui concerne la proposition de certains auteurs (Kim, Phipps et Anselin 2003; Steimetz 2010; Dubé et Legros 2014; Dubé et al. 2017), les effets marginaux (figure 3.5) peuvent être exprimés par la décomposition suivante lorsque la matrice de pondération est standardisée en ligne :
Effet direct : \(\beta_k\).
Effet total : \(\frac{{(\beta}_k+\theta_k)}{(1-\rho)}\).
Effet indirect : effet total – effet direct = \(\frac{{(\rho\beta}_k+\theta_k)}{(1-\rho)}\).
À noter que les logiciels statistiques retournent les effets marginaux sur la base de la décomposition suggérée par LeSage et Pace (2009), issue de l’approximation du produit matriciel. Si l’effet marginal total est identique dans les deux cas, la différence vient essentiellement de la manière de calculer l’effet marginal direct, qui influence également le calcul de l’effet marginal indirect obtenu par soustraction.
3.1.4.2 Modèle SDM dans R
Le modèle SDM est construit avec la fonction lagsarlm du package spatialreg. Notez que le paramètre type = "mixed" spécifie l’utilisation d’un modèle mixte.
## Construction du modèle
modele_SDM <- lagsarlm(NO2 ~ Pct0_14 + Pct_65 + Pct_Img + Pct_brevet + NivVieMed,
listw = w_rook, # matrice de pondération spatiale
data = LyonIris, # dataframe
type = "mixed")
## Résultats du modèle
summary(modele_SDM, Nagelkerke = TRUE)
Call:lagsarlm(formula = NO2 ~ Pct0_14 + Pct_65 + Pct_Img + Pct_brevet +
NivVieMed, data = LyonIris, listw = w_rook, type = "mixed")
Residuals:
Min 1Q Median 3Q Max
-12.60922 -1.77753 -0.43909 0.99252 18.15526
Type: mixed
Coefficients: (asymptotic standard errors)
Estimate Std. Error z value Pr(>|z|)
(Intercept) 8.1130457 2.5671301 3.1604 0.001576
Pct0_14 -0.0574046 0.0344908 -1.6643 0.096043
Pct_65 -0.0238715 0.0293647 -0.8129 0.416256
Pct_Img 0.0048364 0.0266560 0.1814 0.856025
Pct_brevet 0.0112746 0.0195259 0.5774 0.563656
NivVieMed -0.1463876 0.0605853 -2.4162 0.015682
lag.Pct0_14 -0.1242574 0.0581170 -2.1381 0.032512
lag.Pct_65 0.0255480 0.0499646 0.5113 0.609125
lag.Pct_Img 0.1559952 0.0482138 3.2355 0.001214
lag.Pct_brevet -0.0883930 0.0342496 -2.5809 0.009856
lag.NivVieMed 0.1032469 0.0960201 1.0753 0.282257
Rho: 0.84127, LR test value: 492.38, p-value: < 2.22e-16
Asymptotic standard error: 0.023363
z-value: 36.009, p-value: < 2.22e-16
Wald statistic: 1296.7, p-value: < 2.22e-16
Log likelihood: -1353.106 for mixed model
ML residual variance (sigma squared): 9.9845, (sigma: 3.1598)
Nagelkerke pseudo-R-squared: 0.8002
Number of observations: 506
Number of parameters estimated: 13
AIC: 2732.2, (AIC for lm: 3222.6)
LM test for residual autocorrelation
test value: 0.0748, p-value: 0.78447Effets directs, indirects et totaux
# Effets directs, indirects et totaux (uniquement les coefficients)
impacts(modele_SDM, listw = w_rook, R = 999)Impact measures (mixed, exact):
Direct Indirect Total
Pct0_14 -0.12369039 -1.02079497 -1.14448536
Pct_65 -0.02177191 0.03233406 0.01056215
Pct_Img 0.06632543 0.94692639 1.01325182
Pct_brevet -0.01903815 -0.46681402 -0.48585217
NivVieMed -0.15403413 -0.11775603 -0.27179016# Effets directs, indirects et totaux (coefficients, valeurs de z et de p)
summary(impacts(modele_SDM, listw = w_rook, R = 999), zstats = TRUE, short = TRUE)Impact measures (mixed, exact):
Direct Indirect Total
Pct0_14 -0.12369039 -1.02079497 -1.14448536
Pct_65 -0.02177191 0.03233406 0.01056215
Pct_Img 0.06632543 0.94692639 1.01325182
Pct_brevet -0.01903815 -0.46681402 -0.48585217
NivVieMed -0.15403413 -0.11775603 -0.27179016
========================================================
Simulation results ( variance matrix):
========================================================
Simulated standard errors
Direct Indirect Total
Pct0_14 0.04463467 0.3441166 0.3736960
Pct_65 0.03579361 0.2762292 0.2977919
Pct_Img 0.03295862 0.2746845 0.2946535
Pct_brevet 0.02499757 0.2017782 0.2181867
NivVieMed 0.06890036 0.5020965 0.5378595
Simulated z-values:
Direct Indirect Total
Pct0_14 -2.7617672 -2.9797239 -3.07373662
Pct_65 -0.5910544 0.1030813 0.02457457
Pct_Img 2.0491014 3.5177116 3.50851509
Pct_brevet -0.7920982 -2.3600183 -2.27328637
NivVieMed -2.2580178 -0.2208383 -0.49540885
Simulated p-values:
Direct Indirect Total
Pct0_14 0.0057489 0.00288508 0.00211396
Pct_65 0.5544840 0.91789841 0.98039430
Pct_Img 0.0404522 0.00043529 0.00045062
Pct_brevet 0.4283034 0.01827403 0.02300893
NivVieMed 0.0239446 0.82521838 0.62031155Dépendance spatiale du modèle SDM?
Avec une valeur du I de Moran de -0,005 (p > 0,10), les résidus du modèle SDEM ne sont pas spatialement autocorrélés.
moran.mc(resid(modele_SDM), w_rook, nsim = 999)
Monte-Carlo simulation of Moran I
data: resid(modele_SDM)
weights: w_rook
number of simulations + 1: 1000
statistic = -0.0046127, observed rank = 490, p-value = 0.51
alternative hypothesis: greater3.1.5 Modèle SDEM : autocorrélation spatiale sur les variables indépendantes et sur le terme d’erreur
3.1.5.1 Description du modèle SDEM
Une autre variante permettant de tirer profit de l’avantage des régressions spatiales, c’est-à-dire l’introduction d’effets liés aux externalités spatiales des observations, consiste à jumeler les modèles SLX et SEM pour obtenir le modèle Durbin avec termes d’erreurs spatialement liés (SDEM - Spatial Durbin Error Model). Le modèle s’écrit :
\[ \mathbf{y}=\mathbf{\iota}\alpha+\mathbf{X\beta}+\mathbf{WX\theta}+\mathbf{\nu} \\ \tag{3.12}\]
\[ \mathbf{\nu}=\lambda\mathbf{W\nu}+\mathbf{\varepsilon} \]
Tout comme pour les spécifications SAR, SEM et SDM, le modèle SDEM ne peut être estimé par la méthode des moindres carrés ordinaire et nécessite une méthode d’estimation appropriée.
Entre le modèle SEM et le modèle SDEM, il est clairement avantageux d’opter pour une spécification SDEM si le but est d’intégrer des effets spatiaux et de tenir compte des possibles relations spatiales dans l’interprétation des résultats de régression. Le calcul des effets marginaux (figure 3.6) permet de tenir compte de la spécificité des externalités spatiales.
\[ \frac{\partial\mathbf{y}}{\partial\mathbf{x}_\mathbf{k}}={\mathbf{I}\beta}_k+\mathbf{W}\theta_k \tag{3.13}\]
Dans le cas où la matrice de pondération spatiale \(\mathbf{W}\) est standardisée en ligne, l’interprétation des effets marginaux est plutôt simple et directe :
\(\beta_k\) est l’effet marginal direct.
\(\theta_k\) est l’effet marginal indirect et l’effet d’externalité spatiale.
\(\beta_k+\theta_k\) est l’effet marginal total.
Finalement, comme pour les spécifications précédentes, il est sage de vérifier, avec l’aide d’une statistique générale, si les résidus du modèle permettent de ne pas rejeter l’hypothèse d’indépendance entre les termes d’erreurs. Or, puisque la structure spatiale est explicitement intégrée dans le terme d’erreur du modèle, cette spécification réussit généralement à contrôler le problème de manière efficace.
3.1.5.2 Modèle SDEM dans R
Construction du modèle SDEM dans R
Le modèle SDEM est construit avec la fonction errorsarlm du package spatialreg. Notez que le paramètre etype = "mixed" spécifie l’utilisation d’un modèle mixte.
## Construction du modèle
modele_SDEM <- errorsarlm(NO2 ~ Pct0_14 + Pct_65 + Pct_Img + Pct_brevet + NivVieMed,
listw = w_rook, # matrice de pondération spatiale
data = LyonIris, # dataframe
etype = 'emixed')
## Résultats du modèle
summary(modele_SDEM, Nagelkerke = TRUE)
Call:errorsarlm(formula = NO2 ~ Pct0_14 + Pct_65 + Pct_Img + Pct_brevet +
NivVieMed, data = LyonIris, listw = w_rook, etype = "emixed")
Residuals:
Min 1Q Median 3Q Max
-12.99324 -1.82407 -0.45644 1.06084 18.21108
Type: error
Coefficients: (asymptotic standard errors)
Estimate Std. Error z value Pr(>|z|)
(Intercept) 37.061010 6.501018 5.7008 1.192e-08
Pct0_14 -0.081998 0.041699 -1.9664 0.04925
Pct_65 -0.026329 0.034714 -0.7585 0.44817
Pct_Img 0.004656 0.031028 0.1501 0.88072
Pct_brevet 0.009785 0.023884 0.4097 0.68203
NivVieMed -0.167855 0.068005 -2.4683 0.01358
lag.Pct0_14 -0.176747 0.102345 -1.7270 0.08417
lag.Pct_65 0.010533 0.089183 0.1181 0.90599
lag.Pct_Img 0.092785 0.079704 1.1641 0.24437
lag.Pct_brevet -0.038048 0.056688 -0.6712 0.50211
lag.NivVieMed -0.102531 0.172405 -0.5947 0.55204
Lambda: 0.8976, LR test value: 464.09, p-value: < 2.22e-16
Asymptotic standard error: 0.018242
z-value: 49.204, p-value: < 2.22e-16
Wald statistic: 2421, p-value: < 2.22e-16
Log likelihood: -1367.25 for error model
ML residual variance (sigma squared): 10.046, (sigma: 3.1696)
Nagelkerke pseudo-R-squared: 0.78871
Number of observations: 506
Number of parameters estimated: 13
AIC: 2760.5, (AIC for lm: 3222.6)Effets directs, indirects et totaux
## Effets directs, indirects et totaux (uniquement les coefficients)
impacts(modele_SDEM, listw = w_rook, R = 999)Impact measures (SDEM, glht):
Direct Indirect Total
Pct0_14 -0.081997642 -0.17674683 -0.25874447
Pct_65 -0.026329370 0.01053248 -0.01579689
Pct_Img 0.004656039 0.09278511 0.09744115
Pct_brevet 0.009784961 -0.03804813 -0.02826317
NivVieMed -0.167855498 -0.10253070 -0.27038620## Effets directs, indirects et totaux (coefficients, valeurs de z et de p)
summary(impacts(modele_SDEM, listw = w_rook, R = 999), zstats = TRUE, short = TRUE)Impact measures (SDEM, glht, n):
Direct Indirect Total
Pct0_14 -0.081997642 -0.17674683 -0.25874447
Pct_65 -0.026329370 0.01053248 -0.01579689
Pct_Img 0.004656039 0.09278511 0.09744115
Pct_brevet 0.009784961 -0.03804813 -0.02826317
NivVieMed -0.167855498 -0.10253070 -0.27038620
========================================================
Standard errors:
Direct Indirect Total
Pct0_14 0.04169878 0.10234506 0.13146453
Pct_65 0.03471367 0.08918350 0.11192948
Pct_Img 0.03102807 0.07970364 0.09949722
Pct_brevet 0.02388387 0.05668833 0.07344175
NivVieMed 0.06800483 0.17240549 0.21172909
========================================================
Z-values:
Direct Indirect Total
Pct0_14 -1.9664279 -1.7269698 -1.9681695
Pct_65 -0.7584727 0.1180989 -0.1411325
Pct_Img 0.1500589 1.1641264 0.9793354
Pct_brevet 0.4096890 -0.6711810 -0.3848379
NivVieMed -2.4682880 -0.5947067 -1.2770385
p-values:
Direct Indirect Total
Pct0_14 0.049249 0.084173 0.049049
Pct_65 0.448168 0.905989 0.887765
Pct_Img 0.880718 0.244373 0.327414
Pct_brevet 0.682034 0.502105 0.700358
NivVieMed 0.013576 0.552040 0.201589Dépendance spatiale du modèle SDEM?
Avec une valeur du I de Moran de -0,010 (p > 0,10), les résidus du modèle SDEM ne sont pas spatialement autocorrélés.
moran.mc(resid(modele_SDEM), w_rook, nsim = 999)
Monte-Carlo simulation of Moran I
data: resid(modele_SDEM)
weights: w_rook
number of simulations + 1: 1000
statistic = -0.010362, observed rank = 416, p-value = 0.584
alternative hypothesis: greater3.1.6 Modèle généralisé : autocorrélation spatiale de l’ensemble des variables et des composantes du modèle
3.1.6.1 Description du modèle généralisé
Le modèle spatial généralisé (Manski model en anglais), qui est essentiellement une extension du modèle SDM lorsque le processus autorégressif est ajouté aux termes d’erreurs, permet une représentation complète des possibilités. Il permet également de réfléchir à une stratégie du général vers le particulier pour la sélection de la spécification finale :
\[ \mathbf{y}=\lambda\mathbf{Wy}+\mathbf{\iota}\alpha+\mathbf{X\beta}+\mathbf{WX\theta}+\mathbf{\nu} \tag{3.14}\]
\[ \mathbf{\nu}=\lambda\mathbf{W\nu}+\mathbf{\varepsilon} \]
La spécification tient compte, tout comme le modèle SDM, des effets de débordement (ou effets d’entraînement) spatiaux ainsi que des effets d’externalités spatiales.
Le modèle spatial généralisé ne peut être estimé par la méthode des moindres carrés ordinaire. Il faut recourir à la méthode du maximum de vraisemblance ou encore à la méthode des moments généralisés, cette dernière approche offrant une flexibilité intéressante pour la présence d’hétéroscédasticité.
D’une part, certains auteurs notent que des problèmes peuvent survenir lorsque les matrices de pondération spatiale mobilisées pour estimer le modèle sont identiques pour l’ensemble des processus autorégressifs (Le Gallo 2002; Anselin et Bera 1998). D’autre part, Elhorst (2014) suggère d’estimer d’abord cette spécification afin de faire un choix de modèle, puisqu’il procure une structure emboîtée (voir section suivante).
3.1.6.2 Modèle généralisé (Manski) dans R
## Construction du modèle
modele_Manski <- sacsarlm(NO2 ~ Pct0_14 + Pct_65 + Pct_Img + Pct_brevet + NivVieMed,
listw = w_rook, # matrice de pondération spatiale
data = LyonIris, # dataframe
type="sacmixed")
## Résultats du modèle
summary(modele_Manski, Nagelkerke = TRUE)
Call:sacsarlm(formula = NO2 ~ Pct0_14 + Pct_65 + Pct_Img + Pct_brevet +
NivVieMed, data = LyonIris, listw = w_rook, type = "sacmixed")
Residuals:
Min 1Q Median 3Q Max
-12.54832 -1.80538 -0.43054 0.99266 18.04011
Type: sacmixed
Coefficients: (asymptotic standard errors)
Estimate Std. Error z value Pr(>|z|)
(Intercept) 7.7927132 2.8939671 2.6927 0.007087
Pct0_14 -0.0555696 0.0347795 -1.5978 0.110094
Pct_65 -0.0233490 0.0294070 -0.7940 0.427199
Pct_Img 0.0035044 0.0268385 0.1306 0.896114
Pct_brevet 0.0122230 0.0196832 0.6210 0.534608
NivVieMed -0.1463864 0.0606995 -2.4117 0.015880
lag.Pct0_14 -0.1211022 0.0602980 -2.0084 0.044601
lag.Pct_65 0.0258497 0.0495836 0.5213 0.602133
lag.Pct_Img 0.1541563 0.0497015 3.1016 0.001924
lag.Pct_brevet -0.0874516 0.0348103 -2.5122 0.011997
lag.NivVieMed 0.1050658 0.0955590 1.0995 0.271556
Rho: 0.84762
Asymptotic standard error: 0.037124
z-value: 22.832, p-value: < 2.22e-16
Lambda: -0.027606
Asymptotic standard error: 0.11539
z-value: -0.23924, p-value: 0.81092
LR test value: 646.48, p-value: < 2.22e-16
Log likelihood: -1353.074 for sacmixed model
ML residual variance (sigma squared): 9.9326, (sigma: 3.1516)
Nagelkerke pseudo-R-squared: 0.80022
Number of observations: 506
Number of parameters estimated: 14
AIC: 2734.1, (AIC for lm: 3366.6)## Effets marginaux
impacts(modele_Manski, listw = w_rook)Impact measures (sacmixed, exact):
Direct Indirect Total
Pct0_14 -0.12204341 -1.03736491 -1.1594083
Pct_65 -0.02095459 0.03736568 0.0164111
Pct_Img 0.06560041 0.96904739 1.0346478
Pct_brevet -0.01824321 -0.47544430 -0.4936875
NivVieMed -0.15390071 -0.11726571 -0.2711664## Effets marginaux avec les valeurs de z
summary(impacts(modele_Manski,listw = w_rook, R = 500), zstats=TRUE)Impact measures (sacmixed, exact):
Direct Indirect Total
Pct0_14 -0.12204341 -1.03736491 -1.1594083
Pct_65 -0.02095459 0.03736568 0.0164111
Pct_Img 0.06560041 0.96904739 1.0346478
Pct_brevet -0.01824321 -0.47544430 -0.4936875
NivVieMed -0.15390071 -0.11726571 -0.2711664
========================================================
Simulation results ( variance matrix):
Direct:
Iterations = 1:500
Thinning interval = 1
Number of chains = 1
Sample size per chain = 500
1. Empirical mean and standard deviation for each variable,
plus standard error of the mean:
Mean SD Naive SE Time-series SE
Pct0_14 -0.12583 0.04236 0.001894 0.001894
Pct_65 -0.01712 0.03646 0.001630 0.001495
Pct_Img 0.06629 0.03122 0.001396 0.001245
Pct_brevet -0.01773 0.02418 0.001081 0.001081
NivVieMed -0.15468 0.06716 0.003003 0.003003
2. Quantiles for each variable:
2.5% 25% 50% 75% 97.5%
Pct0_14 -0.200440 -0.15545 -0.12609 -0.097687 -0.03878
Pct_65 -0.093195 -0.04081 -0.01496 0.007161 0.05565
Pct_Img 0.007921 0.04413 0.06658 0.088910 0.12554
Pct_brevet -0.066103 -0.03499 -0.01822 -0.002594 0.03407
NivVieMed -0.285740 -0.19952 -0.15582 -0.109910 -0.01650
========================================================
Indirect:
Iterations = 1:500
Thinning interval = 1
Number of chains = 1
Sample size per chain = 500
1. Empirical mean and standard deviation for each variable,
plus standard error of the mean:
Mean SD Naive SE Time-series SE
Pct0_14 -1.06945 0.3803 0.017008 0.015952
Pct_65 0.05870 0.3140 0.014043 0.013187
Pct_Img 1.01838 0.3240 0.014488 0.014577
Pct_brevet -0.47953 0.2163 0.009672 0.007532
NivVieMed -0.08036 0.5353 0.023939 0.023939
2. Quantiles for each variable:
2.5% 25% 50% 75% 97.5%
Pct0_14 -1.7981 -1.2939 -1.04621 -0.8221 -0.3613
Pct_65 -0.5632 -0.1223 0.04566 0.2450 0.6778
Pct_Img 0.5300 0.8086 0.96300 1.1866 1.7548
Pct_brevet -0.9350 -0.5900 -0.46780 -0.3407 -0.1171
NivVieMed -1.1428 -0.3900 -0.10126 0.2157 1.0120
========================================================
Total:
Iterations = 1:500
Thinning interval = 1
Number of chains = 1
Sample size per chain = 500
1. Empirical mean and standard deviation for each variable,
plus standard error of the mean:
Mean SD Naive SE Time-series SE
Pct0_14 -1.19527 0.4055 0.01814 0.016962
Pct_65 0.04158 0.3355 0.01501 0.015005
Pct_Img 1.08467 0.3410 0.01525 0.015308
Pct_brevet -0.49725 0.2310 0.01033 0.008023
NivVieMed -0.23504 0.5685 0.02542 0.023842
2. Quantiles for each variable:
2.5% 25% 50% 75% 97.5%
Pct0_14 -1.9811 -1.4359 -1.18003 -0.93514 -0.42642
Pct_65 -0.6377 -0.1531 0.02099 0.23944 0.68190
Pct_Img 0.5749 0.8589 1.02756 1.26632 1.84599
Pct_brevet -0.9989 -0.6121 -0.48533 -0.35030 -0.09898
NivVieMed -1.3697 -0.5751 -0.25862 0.08621 0.93098
========================================================
Simulated standard errors
Direct Indirect Total
Pct0_14 0.04235555 0.3803002 0.4055261
Pct_65 0.03645725 0.3140183 0.3355230
Pct_Img 0.03121743 0.3239636 0.3410435
Pct_brevet 0.02418199 0.2162766 0.2310370
NivVieMed 0.06715517 0.5352898 0.5684950
Simulated z-values:
Direct Indirect Total
Pct0_14 -2.9707146 -2.8121145 -2.9474653
Pct_65 -0.4694892 0.1869323 0.1239375
Pct_Img 2.1234838 3.1434884 3.1804318
Pct_brevet -0.7331259 -2.2171889 -2.1522722
NivVieMed -2.3032986 -0.1501277 -0.4134429
Simulated p-values:
Direct Indirect Total
Pct0_14 0.0029711 0.0049217 0.0032039
Pct_65 0.6387200 0.8517137 0.9013648
Pct_Img 0.0337133 0.0016695 0.0014706
Pct_brevet 0.4634816 0.0266102 0.0313759
NivVieMed 0.0212620 0.8806639 0.6792821## Autocorrélation spatiale des résidus
moran.mc(resid(modele_Manski), w_rook, nsim = 999)
Monte-Carlo simulation of Moran I
data: resid(modele_Manski)
weights: w_rook
number of simulations + 1: 1000
statistic = -0.0009215, observed rank = 501, p-value = 0.499
alternative hypothesis: greater3.2 Quel modèle choisir?
Évidemment, la question qui brûle les lèvres est de savoir quelle spécification nous devrions retenir pour l’analyse empirique et la présentation des résultats. Deux avenues sont possibles.
D’une part, il est possible que certains impératifs théoriques guident la chercheuse ou le chercheur vers une spécification particulière. Ainsi, si l’on souhaite vérifier comment les caractéristiques des milieux avoisinants influencent une variable d’intérêt, alors les spécifications SLX ou SDEM sont à privilégier puisqu’elles permettent explicitement d’aborder la question. Si l’intérêt est de voir comment une variation locale d’une variable d’intérêt peut avoir de l’influence à la grandeur du territoire, alors la spécification SAR est probablement à privilégier puisqu’elle permet d’évaluer l’impact spatial « global » d’un changement à microéchelle. Il est également possible qu’une question de recherche trouve un écho parmi les deux possibilités, dans lequel des cas le modèle SDM s’avère intéressant.
Si une chercheuse ou un chercheur souhaite essentiellement corriger la présence d’autocorrélation spatiale entre les résidus sans intégrer explicitement de liens spatiaux dans l’interprétation du modèle, alors la spécification SEM peut s’avérer intéressante. Il faut néanmoins avouer que cette correction de l’autocorrélation spatiale n’apporte que peu d’intérêt en ce qui concerne l’interprétation, sauf celui de corriger les écarts-types des coefficients estimés.
D’autre part, le choix peut également être basé sur des considérations plus statistiques. Dans ce cas, on souhaite identifier, sur la base de critères préalablement définis, le modèle qui offre la meilleure performance. Bien que le test de Moran permette de détecter la présence d’autocorrélation spatiale dans les résidus, le test n’est malheureusement pas mobilisable pour tenter d’identifier une spécification préférable.
Il existe trois différentes stratégies de tests : les tests de ratio de vraisemblance, qui nécessitent l’estimation des modèles contraints (les spécifications linéaires classiques) et non contraints (les modèles économétriques spatiaux); les tests de Wald, qui nécessitent aussi l’estimation des modèles contraints et non contraints; et les tests du multiplicateur de Lagrange (ou tests LM), qui nécessitent uniquement l’estimation des modèles contraints.
3.2.1 Tests du multiplicateur de Lagrange (LM) sur le modèle MCO
Une procédure relativement simple existe pour discriminer entre les spécifications SAR, SEM et MCO. Puisque les modèles contraints sont relativement simples et directs, les tests LM sont souvent privilégiés en pratique. Ces tests (en version simple et robuste) ont été largement popularisés par Anselin et al. (1996) pour vérifier si le recours à un modèle autorégressif est nécessaire, comparativement à un modèle de régression classique (MCO).
Les tests sont calculés sur la base des estimations obtenues par MCO pour la spécification linéaire classique et avec l’aide d’une matrice de pondération spatiale préalablement identifiée et calculée. Pour chaque spécification des modèles économétriques spatiaux, il existe une forme spécifique pour les tests-LM. Comment alors comparer les différentes statistiques pour identifier la spécification à retenir?
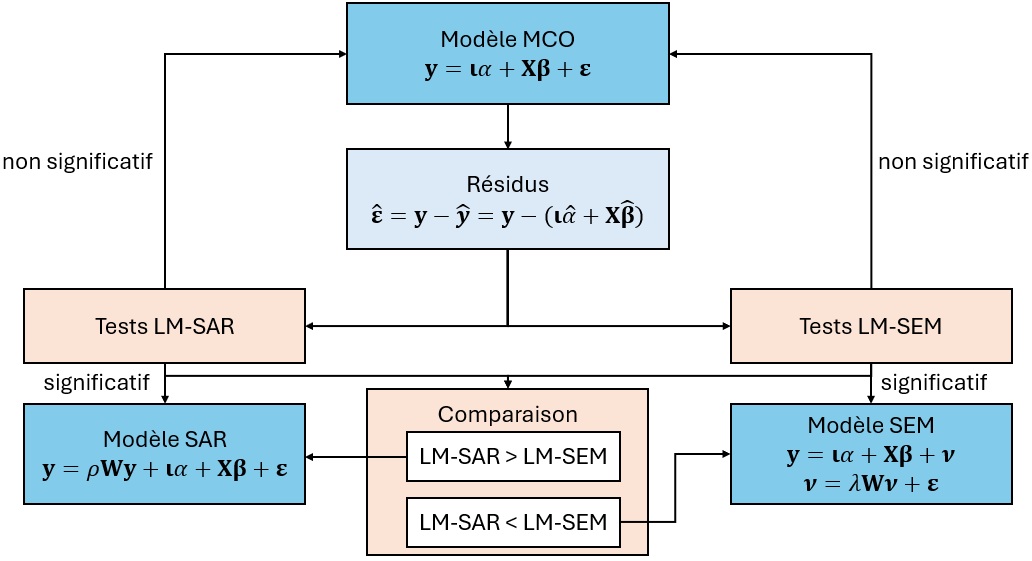
La démarche générale suivante, schématisée à la figure 3.7, peut être utilisée pour guider le choix d’une spécification :
Si toutes les valeurs des tests (simples et robustes) sont non significatives (p > 0,05), alors le recours à un modèle autorégressif n’est pas nécessaire. Nous pouvons conserver le modèle de régression classique (MCO).
Si les valeurs de
LMlagou deRLMlagsont non significatives (p > 0,05), alors le recours au modèle SAR n’est pas nécessaire.Si les valeurs de
LMerrou deRLMerrsont non significatives (p > 0,05), alors le recours au modèle SEM n’est pas nécessaire.Si les valeurs de
RLMlaget deRLMerrsont significatives (p < 0,001), nous choisissons le modèle ayant la plus forte statistique.Si
RLMlag>RLMerr, il est suggéré d’utiliser la spécification SAR.Si
RLMerr>RLMlag, il est suggéré d’utiliser la spécification SEM.
Dans R, ces tests LM sont calculés sur le modèle MCO avec la fonction lm.LMtests et une matrice de pondération spatiale. Dans les résultats ci-dessous, nous ne retenons pas le modèle SEM car la valeur de 0,740 pour le RLMerr n’est pas significative (p = 0,3898). Par contre, les valeurs de LMlag et de RLMlag (555 et 123) sont significatives, ce qui justifie la sélection du modèle SAR.
## Tests de Lagrange
summary(lm.LMtests(model = modele_MCO,
listw = w_rook,
test = c("LMlag","LMerr","RLMlag","RLMerr"))) Rao's score (a.k.a Lagrange multiplier) diagnostics for spatial
dependence
data:
model: lm(formula = NO2 ~ Pct0_14 + Pct_65 + Pct_Img + Pct_brevet +
NivVieMed, data = LyonIris)
test weights: listw
statistic parameter p.value
RSlag 554.65778 1 <2e-16 ***
RSerr 432.83282 1 <2e-16 ***
adjRSlag 122.56452 1 <2e-16 ***
adjRSerr 0.73955 1 0.3898
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 13.2.2 Tests du ratio de vraisemblance sur les modèles spatiaux
En partant de la structure emboîtée que représente le modèle spatial généralisé, il est possible de proposer une stratégie qualifiée de « général vers le particulier » à partir de la significativité des différents paramètres associés aux variables décalées spatialement (figure 3.8). Cette stratégie, basée sur les tests du ratio de vraisemblance qui sont issus de l’estimation des modèles non contraints, dans sa forme la plus générale, et des modèles contraints, dans sa forme la plus spécifique (Elhorst 2014).
En comparant la vraisemblance des modèles, il est possible de vérifier si les deux spécifications sont relativement similaires. Si les vraisemblances sont similaires, la spécification contrainte est préférée à celle non contrainte puisqu’elle est plus parcimonieuse, c’est-à-dire qu’elle permet d’exprimer le même type de relation avec moins de paramètres. Si les vraisemblances sont trop différentes, la spécification générale est alors préférée puisqu’elle permet de mieux expliquer la variable dépendante.
Cette procédure permet également de discriminer entre certaines spécifications intégrant plusieurs processus autorégressifs, tels que les modèles SDM et SDEM par rapport, respectivement, aux modèles SAR et SLX, et SEM et SLX. Elle permet également d’orienter le choix d’une forme fonctionnelle sur un processus de sélection complet, puisque celui considère toutes les formes fonctionnelles et les variantes possibles.
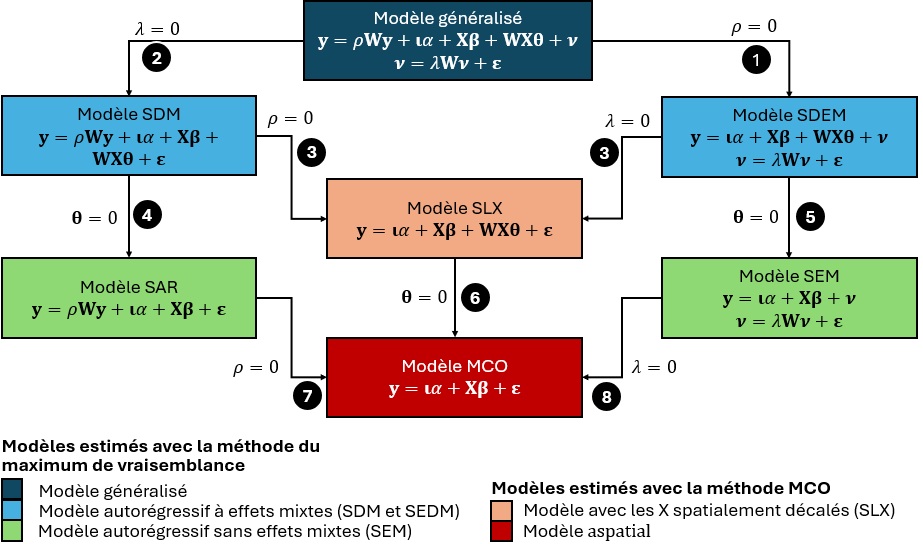
Description de la stratégie « général vers le particulier »
Globalement, la procédure est la suivante :
Étape A. Sélection d’un modèle mixte à partir des coefficients autorégressifs du modèle généralisé :
Si la valeur du coefficient \(\rho\) (rho) n’est pas significativement différente de 0 alors nous calculons le modèle mixte SDEM.
Si la valeur du coefficient \(\lambda\) (lambda) n’est pas significativement différente de 0, alors nous calculons le modèle mixte SDM.
Étape B. Sélection du modèle SLX
- Si les valeurs des coefficients \(\rho\) du modèle SDM et \(\lambda\) du modèle SDEM ne sont pas significativement différentes de 0 alors nous retenons le modèle SLX.
Étape C. Sélection d’un modèle sans effets mixtes
Si la valeur du coefficient \(\rho\) du modèle SDM est significativement différente de 0, mais que tous les coefficients \(\theta\) (theta) des variables indépendantes spatialement décalées \(\mathbf{WX}\) ne sont pas différents de 0, alors nous retenons le modèle SAR.
Si la valeur du coefficient \(\lambda\) du modèle SDEM est significativement différente de 0, mais que tous les coefficients \(\theta\) (theta) des variables indépendantes spatialement décalées \(\mathbf{WX}\) ne sont pas différents de 0, alors nous retenons le modèle SEM.
Étape D. Choix du modèle MCO
Si tous les coefficients \(\theta\) (theta) des variables indépendantes spatialement décalées \(\mathbf{WX}\) du modèle SLX ne sont pas différents de 0, alors nous retenons le modèle aspatial (MCO).
Si le coefficient \(\rho\) (rho) du modèle SAR n’est pas significativement différent de 0, alors nous retenons le modèle aspatial (MCO).
Si le coefficient \(\lambda\) (lambda) du modèle SEM n’est pas significativement différent de 0, alors nous retenons le modèle aspatial (MCO).
Appliquons la stratégie « général vers le particulier » à notre jeu de données. Pour l’étape A, nous constatons que le coefficient lambda n’est pas significativement différent de 0 (\(\lambda =\) -0,028, p = 0,811), contrairement à celle de rho (\(\rho =\) 0,848, p < 0,001). Par conséquent, nous construisons uniquement le modèle SDM.
formule <- 'NO2 ~ Pct0_14 + Pct_65 + Pct_Img + Pct_brevet + NivVieMed'
# Étape A. Sélection d’un modèle mixte à partir
# des coefficients autorégressifs du modèle généralisé
manski <- sacsarlm(formule, listw = w_rook, data = LyonIris, type="sacmixed")
manski_lambda <- list(lambda = manski$lambda,
se = manski$lambda.se,
z = manski$lambda / manski$lambda.se,
p = 2 * (1 - pnorm(abs(manski$lambda / manski$lambda.se))))
manski_rho <- list(rho = manski$rho,
se = manski$rho.se,
z = manski$rho / manski$rho.se,
p = 2 * (1 - pnorm(abs(manski$rho / manski$rho.se))))
manski_resultats <- data.frame(Parametre = c("lambda", "rho"),
Coef = c(manski_lambda$lambda, manski_rho$rho),
z = c(manski_lambda$z, manski_rho$z),
p = c(manski_lambda$p, manski_rho$p))| Paramètre | Coef | z | p |
|---|---|---|---|
| lambda | -0,028 | -0,239 | 0,811 |
| rho | 0,848 | 22,832 | 0,000 |
Les résultats du modèle SDM montrent que :
Pour l’étape B, le coefficient rho (\(\rho =\) 0,841, p < 0,001) est différent de 0, alors nous écartons le modèle SLX.
Pour l’étape C, Plusieurs coefficients \(\theta\) (theta) des variables indépendantes spatialement décalées \(\mathbf{WX}\) ne sont pas différents de 0, notamment
lag.Pct_Imgetlag.Pct_brevet, alors nous écartons aussi le modèle SAR.Au final, nous retenons donc le modèle SDM.
# Modèle Manski
manski <- sacsarlm(formule, listw = w_rook, data = LyonIris, type="sacmixed")
# Modèle SDM
SDM <- lagsarlm(formule, listw = w_rook, data = LyonIris, type = "mixed")
summary(SDM)
Call:lagsarlm(formula = formule, data = LyonIris, listw = w_rook,
type = "mixed")
Residuals:
Min 1Q Median 3Q Max
-12.60922 -1.77753 -0.43909 0.99252 18.15526
Type: mixed
Coefficients: (asymptotic standard errors)
Estimate Std. Error z value Pr(>|z|)
(Intercept) 8.1130457 2.5671301 3.1604 0.001576
Pct0_14 -0.0574046 0.0344908 -1.6643 0.096043
Pct_65 -0.0238715 0.0293647 -0.8129 0.416256
Pct_Img 0.0048364 0.0266560 0.1814 0.856025
Pct_brevet 0.0112746 0.0195259 0.5774 0.563656
NivVieMed -0.1463876 0.0605853 -2.4162 0.015682
lag.Pct0_14 -0.1242574 0.0581170 -2.1381 0.032512
lag.Pct_65 0.0255480 0.0499646 0.5113 0.609125
lag.Pct_Img 0.1559952 0.0482138 3.2355 0.001214
lag.Pct_brevet -0.0883930 0.0342496 -2.5809 0.009856
lag.NivVieMed 0.1032469 0.0960201 1.0753 0.282257
Rho: 0.84127, LR test value: 492.38, p-value: < 2.22e-16
Asymptotic standard error: 0.023363
z-value: 36.009, p-value: < 2.22e-16
Wald statistic: 1296.7, p-value: < 2.22e-16
Log likelihood: -1353.106 for mixed model
ML residual variance (sigma squared): 9.9845, (sigma: 3.1598)
Number of observations: 506
Number of parameters estimated: 13
AIC: 2732.2, (AIC for lm: 3222.6)
LM test for residual autocorrelation
test value: 0.0748, p-value: 0.784473.2.3 Comparaison des modèles mixtes et non mixtes
Avec les tests du ratio de vraisemblance sur les modèles spatiaux, nous pouvons vérifier dans R si le recours d’un modèle mixte est justifié comparativement à un modèle non mixte. Dans le code ci-dessous, nous vérifions si le modèle SDM est statistiquement différent du modèle SAR avec les fonctions LR.Sarlm et anova. Les résultats signalent un écart significatif des valeurs du log-vraisemblance (26,101, p < 0,001). Par conséquent, ce modèle mixte a un apport significatif.
## SDM et SEM sont-ils significativement différents?
LR.Sarlm(modele_SDM, modele_SAR)
Likelihood ratio for spatial linear models
data:
Likelihood ratio = 26.101, df = 5, p-value = 8.528e-05
sample estimates:
Log likelihood of modele_SDM Log likelihood of modele_SAR
-1353.106 -1366.157 anova(modele_SDM, modele_SAR) Model df AIC logLik Test L.Ratio p-value
modele_SDM 1 13 2732.2 -1353.1 1
modele_SAR 2 8 2748.3 -1366.2 2 26.101 8.5283e-05À l’inverse, la différence entre les valeurs du log-vraisemblance des modèles SDEM et SEM n’est pas significative (4,9728, p = 0,42), signalant que l’utilisation d’un modèle SDEM comparativement à un modèle SEM n’est pas nécessaire.
## SDEM et SEM sont-ils significativement différents?
LR.Sarlm(modele_SDEM, modele_SEM)
Likelihood ratio for spatial linear models
data:
Likelihood ratio = 4.9728, df = 5, p-value = 0.4192
sample estimates:
Log likelihood of modele_SDEM Log likelihood of modele_SEM
-1367.250 -1369.737 anova(modele_SDEM, modele_SEM) Model df AIC logLik Test L.Ratio p-value
modele_SDEM 1 13 2760.5 -1367.2 1
modele_SEM 2 8 2755.5 -1369.7 2 4.9728 0.41923.2.4 Mesures AIC et BIC et dépendance spatiale
Bien que la procédure des tests précédente soit intéressante, elle peut néanmoins mener à une certaine difficulté dans l’identification de la forme fonctionnelle préférable. Un arbitrage peut alors être mené à partir de statistiques alternatives telles que les critères d’information.
Le critère d’information d’Akaike (AIC) et le critère d’information bayésien (BIC) sont largement utilisés pour évaluer la qualité d’ajustement du modèle. Plus leurs valeurs sont faibles, plus la spécification est intéressante pour expliquer la variabilité de la variable dépendante, et moins la variabilité du terme d’erreur est grande. Il est donc possible de comparer les valeurs des différents critères afin d’orienter le choix de la spécification finale (MCO, SLX, SAR, SEM, SDM et SDEM).
Nous pouvons aussi comparer l’autocorrélation spatiale des résidus des modèles avec le I de Moran.
## Valeurs d'AIC
AICs <- AIC(modele_MCO, modele_SLX, modele_SAR, modele_SEM,
modele_SDM, modele_SDEM)
## Valeurs de BIC
BICs <- BIC(modele_MCO, modele_SLX, modele_SAR, modele_SEM,
modele_SDM, modele_SDEM)
## Autocorrélation spatiale des résidus
imoran_mco <- moran.mc(resid(modele_MCO), w_rook, nsim = 999)
imoran_slx <- moran.mc(resid(modele_SLX), w_rook, nsim = 999)
imoran_slm <- moran.mc(resid(modele_SAR), w_rook, nsim = 999)
imoran_sem <- moran.mc(resid(modele_SEM), w_rook, nsim = 999)
imoran_sdm <- moran.mc(resid(modele_SDM), w_rook, nsim = 999)
imoran_sdem <- moran.mc(resid(modele_SDEM), w_rook, nsim = 999)
imoran_s <- c(imoran_mco$statistic, imoran_slx$statistic,
imoran_slm$statistic, imoran_sem$statistic,
imoran_sdm$statistic, imoran_sdem$statistic)
imoran_p <- c(imoran_mco$p.value, imoran_slx$p.value,
imoran_slm$p.value, imoran_sem$p.value,
imoran_sdm$p.value, imoran_sdem$p.value)
## Tableau
Comparaison <- data.frame(Modele = c("MCO", "SLX", "SAR", "SEM", "SDM", "SDEM"),
AIC = AICs$AIC,
BIC = BICs$BIC,
dl = AICs$df,
MoranI = imoran_s,
MoranIp = imoran_p)
Comparaison Modele AIC BIC dl MoranI MoranIp
1 MCO 3366.626 3396.212 7 0.587312061 0.001
2 SLX 3222.594 3273.313 12 0.604660275 0.001
3 SAR 2748.314 2782.126 8 -0.014281059 0.654
4 SEM 2755.474 2789.286 8 -0.011826605 0.596
5 SDM 2732.212 2787.157 13 -0.004612686 0.495
6 SDEM 2760.501 2815.446 13 -0.010361653 0.595Quelques lignes de code suffisent pour créer deux graphiques permettant de comparer visuellement les résultats des différents modèles (figure 3.9).
library(ggplot2)
library(ggpubr)
## Graphique pour l'autocorrélation spatiale
g1 <- ggplot(data=Comparaison, aes(x=reorder(Modele,MoranI), y=MoranI)) +
geom_segment(aes(x=reorder(Modele, MoranI),
xend=reorder(Modele, MoranI),
y=0, yend=MoranI)) +
geom_point( size=4,fill="red",shape=21)+
xlab("Modèle") + ylab("I de Moran")+
labs(title="Autocorrélation spatiale des résidus",
caption="Plus la valeur du I de Moran est faible, \nmoins il y a d'autocorrélation spatiale.")
## Graphique pour les valeurs d'AIC
g2 <- ggplot(data=Comparaison, aes(x=reorder(Modele,AIC), y=AIC)) +
geom_segment(aes(x=reorder(Modele, AIC),
xend=reorder(Modele, AIC),
y=0, yend=AIC)) +
geom_point( size=4,fill="red",shape=21)+
xlab("Modèle") + ylab("AIC")+
labs(title="Qualité d'ajustement du modèle",
caption="Plus la valeur d'AIC est faible, \nplus le modèle est performant.")
## Figure avec les deux graphiques
ggarrange(g1, g2)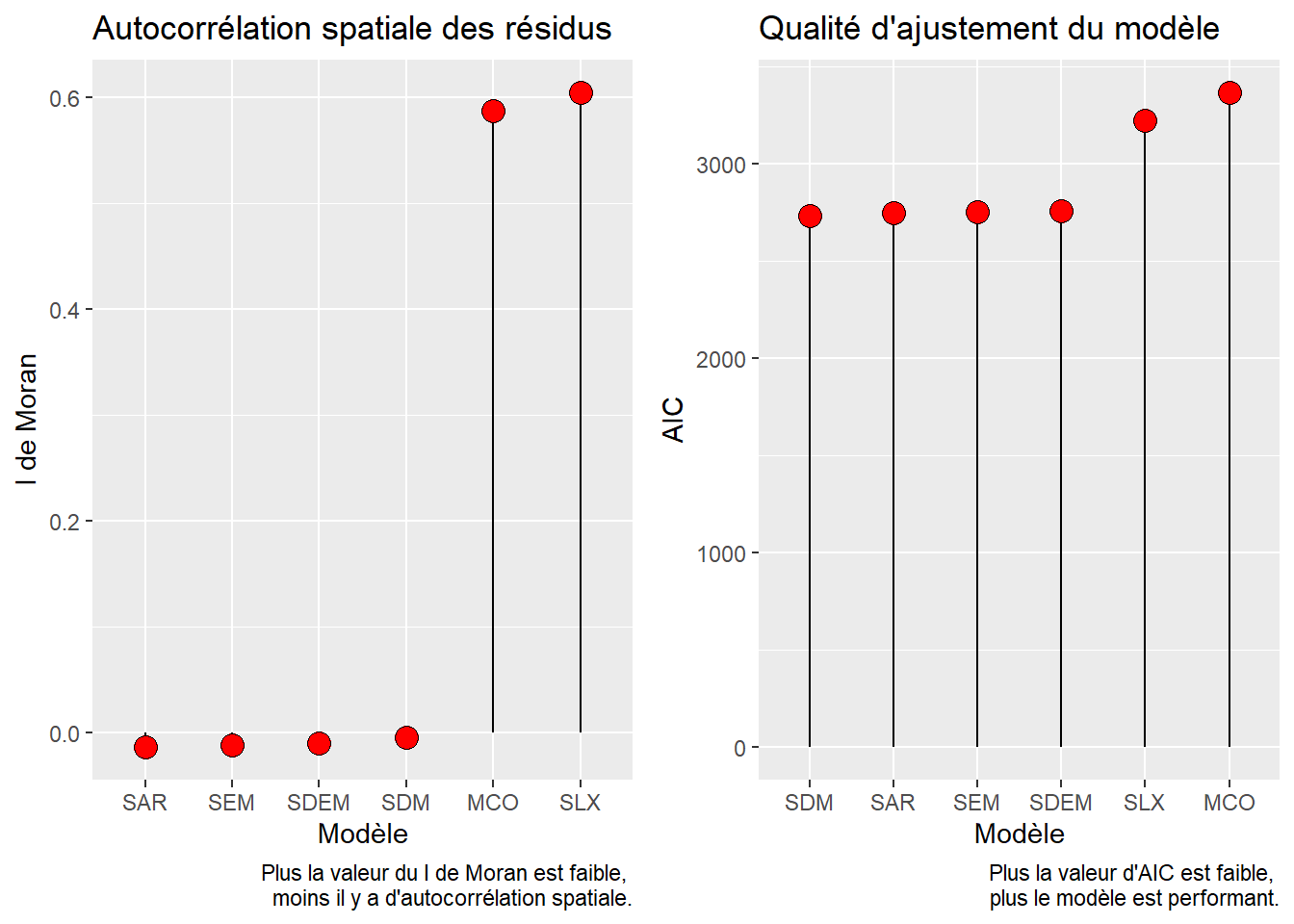
Les résultats démontrent que :
- Les modèles MCO et SLX ont un problème de dépendance spatiale puisque leurs résidus sont significativement autocorrélés spatialement. Par conséquent, ils ne devraient pas être retenus.
- Les modèles SDM, SAR et SEM sont les plus performants avec les valeurs d’AIC les plus faibles.
Quelques lignes de code pour tous les modèles!
formule <- 'NO2 ~ Pct0_14 + Pct_65 + Pct_Img + Pct_brevet + NivVieMed'
MCO <- lm(formule, data = LyonIris)
SLX <- lmSLX(formule, listw = w_rook, data = LyonIris)
SDM <- lagsarlm(formule, listw = w_rook, data = LyonIris, type = "mixed")
SDEM <- errorsarlm(formule, listw = w_rook, data = LyonIris, etype = 'emixed')
SAR <- lagsarlm(formule,listw = w_rook, data = LyonIris, type = 'lag')
SEM <- errorsarlm(formule, listw = w_rook, data = LyonIris)
Manski <- sacsarlm(formule, listw = w_rook, data = LyonIris, type="sacmixed")3.3 Quiz de révision
Dans un modèle SLX, la matrice de pondération spatiale est appliquée au niveau de :
Relisez au besoin la section 3.1.1.
Dans un modèle SAR, la matrice de pondération spatiale est appliquée au niveau de :
Relisez au besoin la section 3.1.2.
Dans un modèle SEM, la matrice de pondération spatiale est appliquée au niveau de :
Relisez au besoin la section 3.1.3.
Dans un modèle mixte SDM, la matrice de pondération spatiale est appliquée au niveau de :
Relisez au besoin la section 3.1.4.
Dans un modèle SDEM, la matrice de pondération spatiale est appliquée au niveau de :
Relisez au besoin la section 3.1.5.
Quelle est la procédure popularisée par Luc Anselin pour discriminer entre les spécifications SAR, SEM et MCO?
Relisez au besoin la section 3.2.1.
3.4 Exercices de révision
Exercice 1. Réalisation de modèles de régression autorégressifs spatiaux
library(sf)
library(spatialreg)
# Matrice de contiguïté selon le partage d’un segment (Rook)
load("data/Lyon.Rdata")
Rook <- poly2nb(LyonIris, queen=FALSE)
w_rook <- nb2listw(Rook, zero.policy=TRUE, style = "W")
# Modèles
formule <- "PM25 ~ Pct0_14 + Pct_65 + Pct_Img + Pct_brevet + NivVieMed"
# Modèles MOC, SLX, SDM, SDEM, SAR, SEM, Manski
à compléterCorrection à la section 11.3.1.
Exercice 2. Tests du multiplicateur de Lagrange (LM) sur le modèle MCO
à compléterCorrection à la section 11.3.2.
Exercice 3. Mesures AIC et BIC et dépendance spatiale
## Valeurs d’AIC et de BIC
à compléter
## Autocorrélation spatiale des résidus
à compléter
## Tableau
Comparaison <- à compléter
ComparaisonCorrection à la section 11.3.3.